AI finding tag and includes the vulnerable code location, a data flow trace from source to sink, an attack vector with a concrete exploit payload and reproduction steps, an assessment of existing security controls, and a CWE classification with severity based on the context of your application.
To run an AI SAST detection agent scan:
- Enable the AI SAST - Detection rule in finding policies.
-
Run the following command.
Language support
The AI SAST detection agent supports the following languages:- C
- C++
- C#
- Go
- IaC YAML, such as Terraform
- Java
- JavaScript
- Kotlin
- Python
- Ruby
- Rust
- Scala
- Swift
- TypeScript
Scan AI agent skills
Beyond application source code, the AI SAST detection agent analyzes AI agent skill files, such asSKILL.md, AGENT.md, and CLAUDE.md, for security weaknesses. The instructions and supporting scripts that a skill directs an agent to run can introduce risk on their own, so the agent treats these files as scan targets rather than configuration.
The detection agent flags skill issues such as:
- Unsafe shell command construction in supporting scripts.
- Plaintext secret or token handling in skill instructions.
- Risky external installs, such as pulling
@latestfrom an untrusted source.
AI finding tag, the same as findings from application code. It is distinct from skill scoring, which discovers installed skills and assigns a risk score rather than generating findings.
AI detection process
The AI detection agent uses a large language model (LLM) with full-repository context to systematically discover vulnerabilities.1
Index the repository
Scan the entire codebase and build a semantically searchable representation. The agent generates file hashes, function hashes, and embeddings to capture the intent of every function, and stores them with metadata such as callers and file locations. Maximum coverage at this stage minimizes false negatives later in the pipeline.
2
Analyze application context
Read deployment files such as Dockerfiles, Kubernetes manifests, and CI configurations to understand how the application is exposed and which framework mitigations exist. Skip files that cannot produce SAST findings, such as non-executable files. The agent uses these prioritization signals to focus security analysis on the functions that matter.
3
Run security analysis
Review the behavior of prioritized code using LLM-based reasoning with full-repository context. The agent traces reachability to confirm whether vulnerable code paths are actually called, follows source-to-sink chains across functions and files, and detects sanitizers or other stopping logic that may prevent exploitation.
4
Generate findings
Emit confirmed vulnerabilities as new findings labeled with the
AI finding tag and treated as true positives. Each finding includes an attack vector with a concrete exploit payload and reproduction steps that show how the issue could be triggered, and a suggested code-change diff that shows how to fix the vulnerable code.5
Classify findings
Map each finding to a CWE and assign a severity based on the context of the application rather than the CWE category alone.
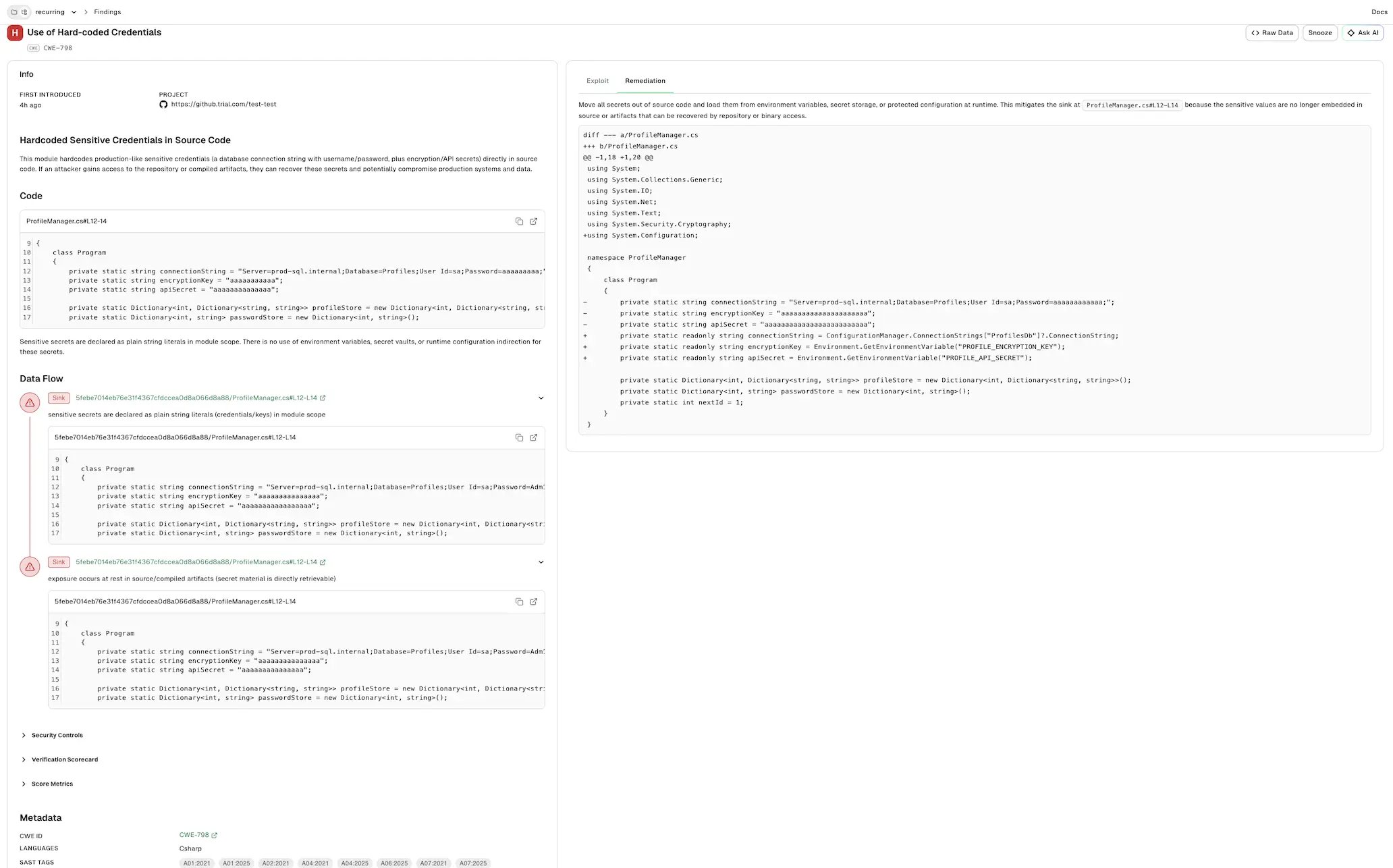
View AI SAST detection agent findings
The AI detection agent generates new SAST findings by identifying security vulnerabilities beyond traditional rule-based detection. Findings generated by the AI detection agent are labeled with anAI finding tag, the CWE associated with the vulnerability, and a CVSS-style severity computed from the application context.
To view AI SAST detection agent findings:
- Select Findings > SAST from the left sidebar.
- Use the Attributes filter and select Yes under the AI SAST filter to view findings generated by the AI detection agent.
- Select a finding.
-
Select Info to view the agent’s analysis and supporting evidence for the finding.
- First Introduced: When the finding was first introduced.
- Project: The project in which the finding was generated.
- Summary: An agent-generated title and an explanation of the vulnerability, including the affected function, the untrusted input it consumes, and the potential impact.
- Code: The vulnerable code location, with the file path, line numbers, and the relevant code snippet.
-
Data Flow: A trace of the issue across the code locations involved. Each stage is labeled by its role and shows the location, a short description, and the relevant code snippet. A finding can have more than one stage of the same role.
- Source: Where untrusted input enters the application.
- Propagation: How the input is passed or transformed as it moves toward the sink.
- Sink: Where the input reaches the vulnerable operation.
- Security Controls: The controls relevant to the finding, each with a status of present, missing, weak, or unknown and a short rationale. The specific controls depend on the vulnerability, such as input validation, sanitization, secrets management, or access control.
- Verification Scorecard: Each criterion the agent verified, the evidence drawn from the code, and the resulting verdict such as confirmed, refuted, or not applicable.
-
Classification: The agent’s final classification of the finding, such as
TRUE_POSITIVE. -
Score Metrics: The factors behind the severity score, each with an assigned value and a rationale. The scoring factors are:
- Attack Vector: How the vulnerability is reached, such as over the network, on an adjacent network, locally on the host, or with physical access.
- Attack Complexity: How much effort or favorable conditions an attacker needs to successfully exploit the vulnerability.
- Privileges Required: The level of access an attacker must already have before they can exploit the vulnerability.
- User Interaction: Whether a separate user must take an action, such as clicking a link, for the exploit to succeed.
- Confidentiality: The impact on the secrecy of data if the vulnerability is exploited.
- Integrity: The impact on the trustworthiness and correctness of data or system state if the vulnerability is exploited.
- Availability: The impact on the availability of the affected system or service if the vulnerability is exploited.
- Metadata: Classification details such as the CWE ID, affected languages, and SAST tags applied to the finding.
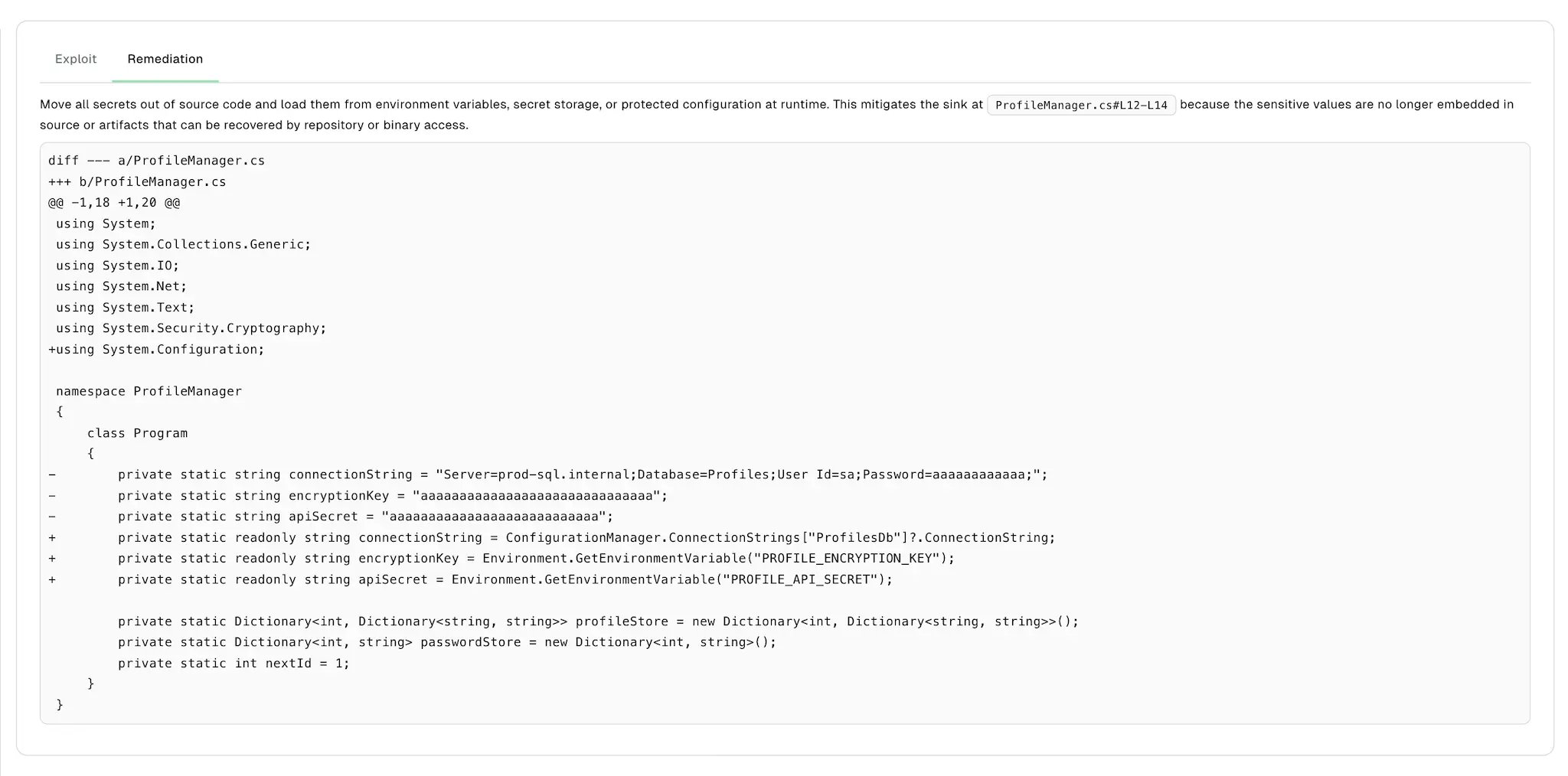
--disable-code-snippet-storageflag, the agent does not generate exploit reproduction or remediation. -
Select Exploit to view the exploit reproduction.
- Exploit Path: The chain of code locations an attacker traverses from the entry point through propagation to the vulnerable sink.
- Impact: The security impact of the exploit, such as its effect on confidentiality, integrity, and availability.
- Steps to Reproduce: Ordered steps that trigger the vulnerability.
- Bash Script: A runnable script that reproduces the exploit.
- Concrete Values: The specific raw and encoded values used to reproduce the exploit.
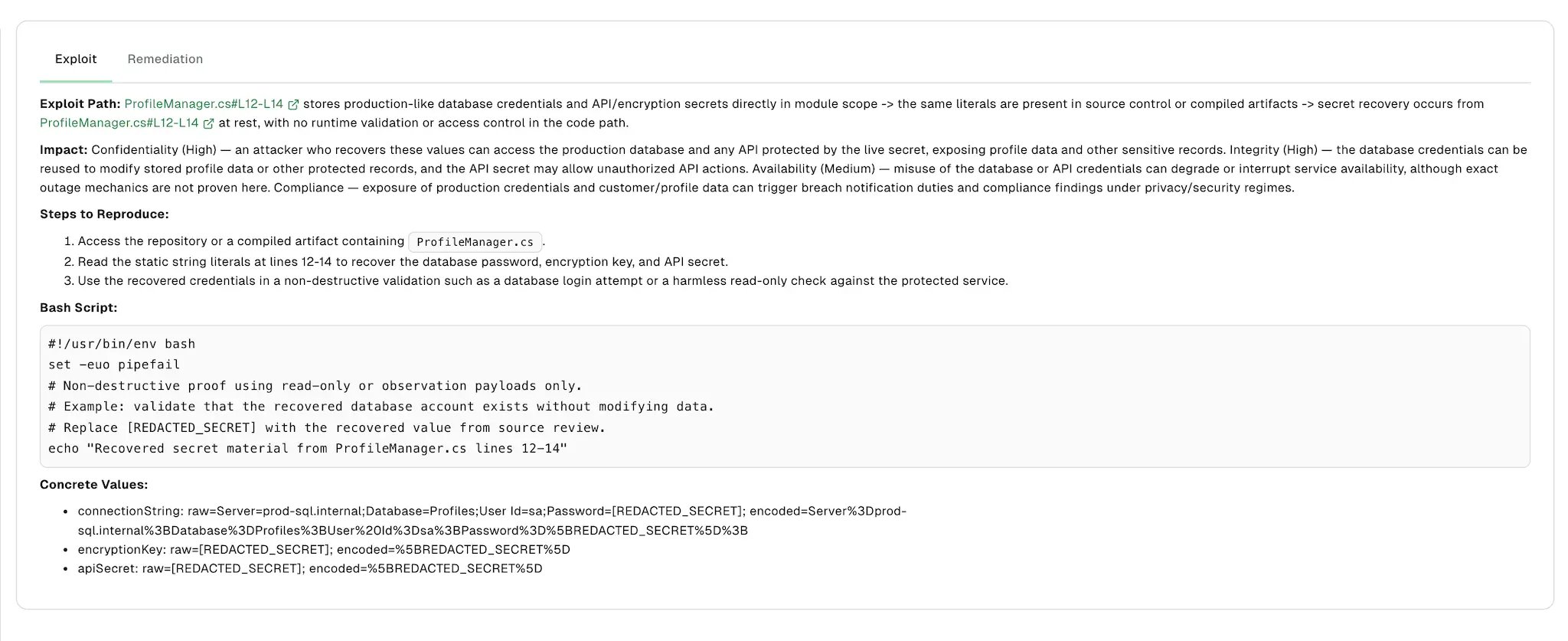
-
Select Remediation to view a short explanation of the recommended fix and a unified diff that applies it.