Python is a high-level, interpreted programming language widely used by developers. Endor Labs supports the scanning and monitoring of Python projects.
Using Endor Labs, application security engineers and developers can:
- Scan their software for potential security issues and violations of organizational policy.
- Prioritize vulnerabilities in the context of their applications.
- Understand the relationships between software components in their applications.
System specifications for deep scan
Before you proceed to run a deep scan, ensure that your system meets the following specification.
| Project Size |
Processor |
Memory |
| Small projects |
4-core processor |
16 GB |
| Mid-size projects |
8-core processor |
32 GB |
| Large projects |
16-core processor |
64 GB |
Software prerequisites
Ensure that the following prerequisites are complete:
- Install Python 3.6 or higher versions. Refer to the Python documentation for instructions on how to install Python.
- For UV managed projects, Python 3.8 or higher is required. To enable UV support, set the environment variable
ENDOR_SCAN_ENABLE_UV_PACKAGE_MANAGER=true.
- Ensure that the package manager pip, Poetry, PDM, UV, or Pipenv is used by your projects to build your software packages.
- If you are using pip with Python 3.12 or higher versions, install setuptools.
- Set up any build, code generation, or other dependencies that are required to install your project’s packages.
- Organize the project as one or more packages using
setup.py, setup.cfg, pyproject.toml, or requirements.txt package manifest files.
- Make sure your repository includes one or more files with
.py extension or pass either one of requirements.txt, setup.py, setup.cfg or pyproject.toml using the --include-path flag. See Scoping scans.
Build Python projects
Creating a virtual environment and building your Python projects before running the endorctl scan is recommended for the most accurate results. Endor Labs attempts to automatically create and configure a virtual environment when one is not provided, but this may not work for complex projects. Ensure that the packages are downloaded into the local package caches and that the build artifacts are present in the standard locations.
- Configure any private repositories
- If you use dependencies from a PyPI compatible repository other than
pypi.org, configure it in the Integrations section of the Endor Labs web application. See Configure private PyPI package repositories for more details.
- Clone the repository and optionally create a virtual environment inside it
-
Clone the repository using git clone or an equivalent workflow.
-
Enter the working copy root directory that’s created.
-
Create a virtual environment based on your package manager:
For pip or setuptools
- Use
python3 -m venv venv. Set up the virtual environment in the root folder that you want to scan and name it venv or .venv.
- Install your project’s dependencies using
venv/bin/python -m pip install -r requirements.txt or venv/bin/python -m pip install.
- If the virtual environment is created outside the project, use one of the ways defined in Virtual environment support to specify the path of the Python virtual environment to Endor Labs.
For Poetry projects
- Install your project’s dependencies using
poetry install.
For PDM projects
- Install your project’s dependencies using
pdm install.
For Pipenv projects
- Run
pipenv install in the project directory. This creates a Pipfile.lock (if it doesn’t exist) and sets up a virtual environment while installing the required packages.
Virtual environment support
Creating a virtual environment is recommended to ensure consistent and accurate scan results, and to verify that all dependencies install correctly before scanning. Automatic setup may encounter issues such as:
- Complex dependency chains or conflicting package requirements
- Private packages requiring authentication
- System-level dependencies not available in the scan environment
- Non-standard project structures or custom build scripts
Endor Labs attempts to automatically detect, create, or configure virtual environments for your projects. The behavior varies by package manager.
Poetry, Pipenv, and PDM
endorctl automatically detects and uses existing virtual environments managed by these tools.
UV
endorctl automatically creates a temporary virtual environment and deletes it after the scan is complete. UV must be installed on your system for this automatic management to work.
pip
endorctl attempts to detect virtual environments in standard locations, such as venv or .venv directories in your project root. You can also use one of the following methods to specify the virtual environment:
-
Set up the virtual environment in the root folder that you want to scan and name it venv or .venv, it is automatically picked up by the Endor Labs application.
export PYTHONPATH=/usr/tmp/venv:/usr/tmp/another-venv
-
Set the environment variable ENDOR_SCAN_PYTHON_VIRTUAL_ENV to the path of the virtual environment of your Python project.
export ENDOR_SCAN_PYTHON_VIRTUAL_ENV=/usr/tmp/venv
-
Set the environment variable ENDOR_SCAN_PYTHON_GLOBAL_SITE_PACKAGES to true to indicate that a virtual environment is not present and Endor Labs can use the system-wide Python installation packages and modules.
export ENDOR_SCAN_PYTHON_GLOBAL_SITE_PACKAGES=true
Note
Setting both ENDOR_SCAN_PYTHON_VIRTUAL_ENV and ENDOR_SCAN_PYTHON_GLOBAL_SITE_PACKAGES environment variables at the same time is currently not supported, and the scan may not be successful.
If you do not set up the virtual environment, Endor Labs attempts to set it up with all the code dependencies, however, we recommend that you install all dependencies in a virtual environment for the most accurate results.
If you are using custom scripts without manifest files to assemble your dependencies, make sure to set up the virtual environment and install the dependencies.
Endor Labs supports fetching and scanning dependencies from private PyPI package registries. Endor Labs will fetch resources from authenticated endpoints and perform the scan, allowing you to view the resolved dependencies and findings. See PyPI package manager integrations for more information on configuring private registries.
Run a scan
Use the following options to scan your repositories. Perform the endorctl scan after building the projects.
Option 1 - Quick scan
Perform a quick scan to get quick visibility into your software composition and perform dependency resolution. It discovers dependencies that the package has explicitly declared. If the package’s build file is incomplete then the dependency list will also be incomplete. This scan won’t perform reachability analysis to help you prioritize vulnerabilities.
endorctl scan --quick-scan
You can perform the scan from within the root directory of the Git project repository, and save the local results to a results.json file. The results and related analysis information are available on the Endor Labs user interface.
endorctl scan --quick-scan -o json | tee /path/to/results.json
You can sign in to the Endor Labs user interface, click the Projects on the left sidebar, and find your project to review its results.
Option 2 - Deep scan
Use the deep scan to perform dependency resolution, reachability analysis, and generate call graphs. You can do this after you complete the quick scan successfully.
The deep scan performs the following operations for the Python projects.
- Discovers explicitly declared dependencies,
- Discovers project dependent OSS packages present in the
venv/global and scope/python.
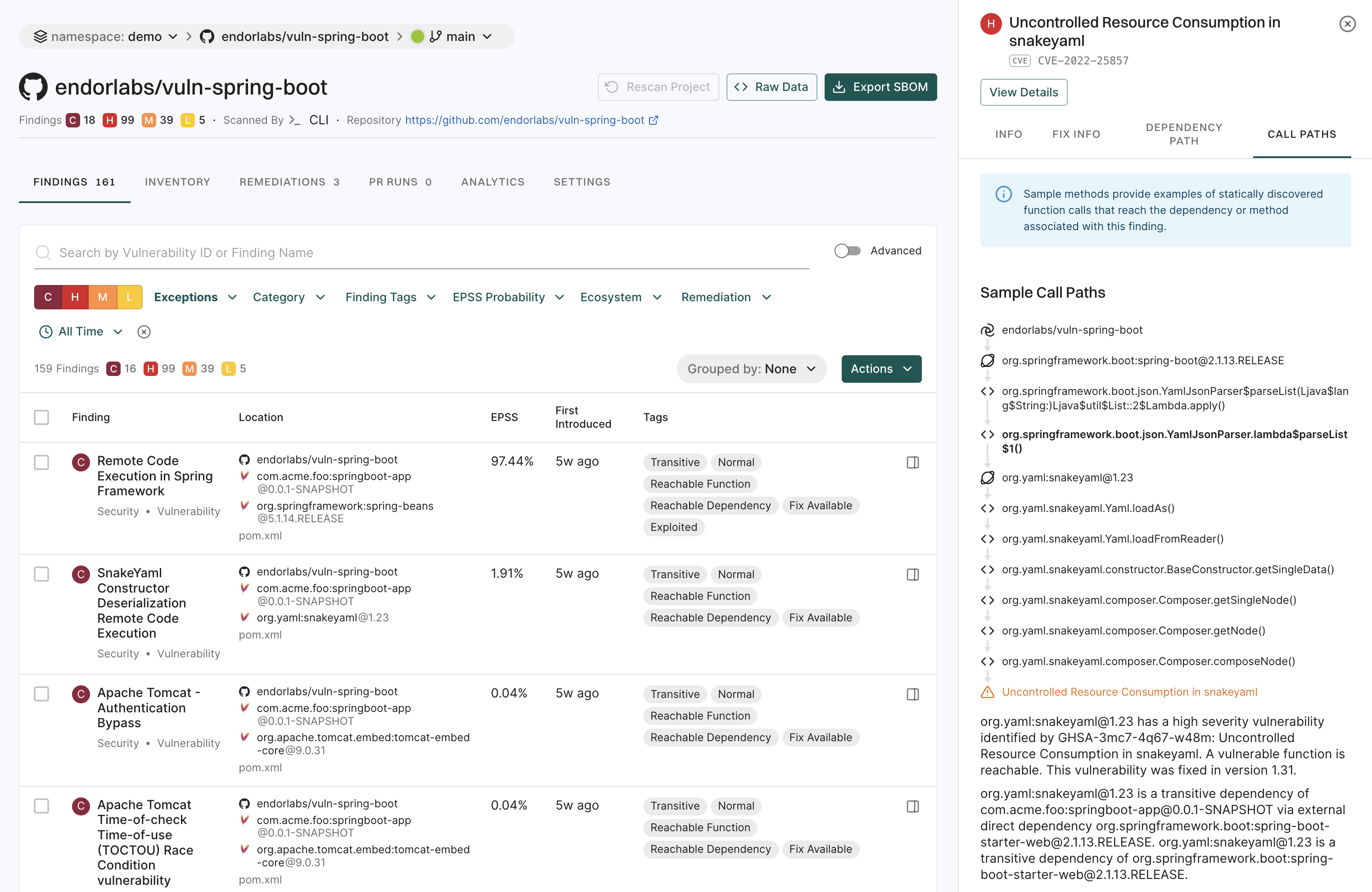
- Performs reachability analysis and generates call graphs.
- Detects dependencies used in source code but not declared in the package’s manifest files called
phantom dependencies.
Use the following flags to save the local results to a results.json file. The results and related analysis information are available on the Endor Labs user interface.
endorctl scan -o json | tee /path/to/results.json
When a deep scan is performed all private software dependencies are completely analyzed by default if they have not been previously scanned. This is a one-time operation and will slow down initial scans, but won’t impact subsequent scans.
Organizations might not own some parts of the software internally and the related findings are not actionable by them. They can choose to disable this analysis using the flag disable-private-package-analysis. By disabling private package analysis, teams can enhance scan performance but may lose insights into how applications interact with first-party libraries.
You can sign in to the Endor Labs user interface, click the Projects on the left sidebar, and find your project to review its results.
Understand the scan process
Endor Labs uses the following two methods to analyze your Python code.
Endor Labs uses the results from both these methods to perform superior dependency resolution, identify security issues, detect open-source vulnerabilities, and generate call graphs.
Dependency resolution using manifest files
In this method, Endor Labs analyzes the manifest files present in a project to detect and resolve dependencies. The manifest files are analyzed in the following priority.
| Package manager |
Priority |
Build solution |
| Poetry |
1 |
poetry.lock,pyproject.toml |
| Pipenv |
2 |
Pipfile.lock,Pipfile |
| PDM |
3 |
pdm.lock,pyproject.toml |
| UV |
4 |
uv.lock,pyproject.toml |
| pip |
5 |
setup.py,setup.cfg,requirements.txt,pyproject.toml |
For Poetry, PDM, and UV, when both lock and toml files are present, both files are analyzed to detect and resolve dependencies.
For pip, the dependency resolution is as follows, where the first available file in the priority list is analyzed to detect and resolve dependencies, and others are ignored.
| Build solution |
Priority |
setup.py |
1 |
setup.cfg |
2 |
pyproject.toml |
3 |
requirements.txt |
4 |
On initialization of a scan, Endor Labs identifies the package manager by inspecting files such as the pyproject.toml, poetry.lock, pdm.lock, setup.py, and requirements.txt. When the files, poetry.lock or pyproject.tomlfiles are discovered, Endor Labs will use the Poetry package manager to build the project. When the files, pdm.lock or pyproject.toml files are discovered, Endor Labs will use the PDM package manager. Otherwise, it will use pip3.
Example
This is an example that demonstrates scanning a Python repository from GitHub on your local system using the endorctl scan.
Here we are assuming that you are running the scan on a Linux or Mac operating system environment and that you have the following Endor Labs API key and secret stored in the environment variables. See endorctl flags and variables.
ENDOR_API_CREDENTIALS_KEY set to the API keyENDOR_API_CREDENTIALS_SECRET set to the API secretENDOR_NAMESPACE set to your namespace (you can find this when logged into Endor Labs by looking at your URL: https://app.endorlabs.com/t/NAMESPACE/...; it is typically a form of your organization’s name)
pip
git clone https://github.com/HybirdCorp/creme_crm.git
cd creme_crm
python3 -m venv venv
source venv/bin/activate
venv/bin/python3 -m pip install
endorctl scan
Poetry
git clone https://github.com/HybirdCorp/creme_crm.git
cd creme_crm
poetry lock
endorctl scan
PDM
git clone https://github.com/HybirdCorp/creme_crm.git
cd creme_crm
pdm install
endorctl scan
UV
git clone https://github.com/example/repo.git
cd repo
endorctl scan
Pipenv
git clone https://github.com/example/repo.git
cd repo
pipenv install
endorctl scan
The scan for this repository is expected to be completed in a few minutes depending on the size of the project.
You can now visit app.endorlabs.com, navigate to Projects, and choose the helloflas/flask-examples project to see your scan results.
Handling custom and multiple requirement files in pip
In some organizations, custom file names, such as default.txt, are used for requirement files instead of the standard requirements.txt. Additionally, some repositories may include multiple requirement files with different names.
To specify custom file names as requirement files, export the file name using the ENDOR_SCAN_PYTHON_REQUIREMENTS environment variable and then run the endorctl scan.
export ENDOR_SCAN_PYTHON_REQUIREMENTS=default.txt
To resolve dependencies from multiple requirement files, export them as a comma-separated list using the ENDOR_SCAN_PYTHON_REQUIREMENTS environment variable and then run the endorctl scan.
export ENDOR_SCAN_PYTHON_REQUIREMENTS=default.txt,requirements.txt
Note
When the ENDOR_SCAN_PYTHON_REQUIREMENTS environment variable is used, only the file names specified in the variable are considered for dependency analysis. For example, if you export default.txt and also have requirements.txt in your repository, requirements.txt will not be considered.
Dependency resolution using static analysis
All Python projects do not always include manifest files. A project can be a series of install statements that are assembled by custom scripts. Even when manifest files are present, the dependency information and version declared in the manifest file may be drastically different from what is used in a project.
To solve this problem, Endor Labs has developed a unique method for dependency resolution by performing a static analysis on the code, giving you complete visibility of what is used in your code.
- Endor Labs enumerates all Python packages and recognizes the import statements within the project. An import statement is a Python code statement that is used to bring external modules or libraries into your Python script.
- It performs a static analysis of the code to match the import statements with the pre-installed packages and recursively traverses all files to create a dependency tree with the actual versions that are installed in the virtual environment.
- It detects the dependencies at the system level to identify which ones are resolved and retrieves the precise name and version information from the library currently in use.
- Also, it gives you accurate visibility into your project components and helps you understand how the components depend on one another.
Through this approach, Endor Labs conducts comprehensive dependency management, assesses reachability, and generates integrated call graphs.
Note
Dependency resolution using static analysis is performed on deep scans only.
Known Limitations
- Endor Labs specifically looks for the requirements.txt file for a Python project using pip. If you use a different file name, it won’t be automatically discovered.
- Python versions older than 3.7 are not supported but may work as expected.
- If a virtual environment is not provided, Python version constraints are not assumed based on the runtime environment of CI. Dependencies are shown for all possible versions of Python at runtime. If a virtual environment is provided, Endor Labs respects what is installed in the virtual environment.
- Symbolic links into manifest files may result in the same package being duplicated in the project.
- If a dependency is not available in the PyPI repository or in a configured private package repository, Endor Labs will be unable to build the software and scans may fail without first building the package in the local environment successfully.
- A project is treated as UV-managed if its
pyproject.toml file contains the tool.uv key. Additionally, any member of a UV workspace is also considered UV-managed, even if its individual manifest file does not include the tool.uv key.
- When scanning UV workspaces, Endor Labs uses the workspace-level lock file for dependency resolution. Individual workspace members are not scanned as independent projects, ensuring consistency with UV’s workspace architecture.
- Inline script dependencies defined within Python script files are not currently detected during scanning.
Call Graph Limitations
- Function calls using dispatch table calls might not be included in the call graph.
- Function calls using unresolved variables might not be included in the call graph.
- Dynamically modified or extended function calls used to declare methods or attributes at run time might not be included in the call graph.
- Functions called indirectly through a function pointer and not by their direct name, might not be included in the call graph.
- Type stubs that provide hints or type annotations for functions, methods, and variables in your Python modules or libraries have to be installed manually before performing a scan.
- If your project has a
pyproject.toml file that includes tools.pyright section, it overrides Endor Labs settings for Pyright and may result in incorrect call graph results. You will need to remove the tools.pyright section from the pyproject.toml file.
Troubleshoot errors
Here are a few error scenarios that you can check for and attempt to resolve them.
Virtual environment errors
You can identify the errors that may occur during virtual environment installation by looking for the following message in the error logs: failed to create virtual environment or failed to install dependencies.
Missing environment dependency
If your code depends on packages such as psycopg2, environment dependencies such as PostgreSQL are also required. The endorctl scan may fail if the environment where it is running does not have PostgreSQL installed.
Incompatible Python version
The default Python version in the environment where the endorctl scan is running is incompatible with one or more of the dependencies that are needed by the code.
Incompatible architecture
One or more dependencies are not compatible with the operating system architecture of the local system on which you are running the endorctl scan. For example, projects with dependency on PyObjC can be run on Mac-based systems, but not Linux systems. A few Python libraries are incompatible with x32 architectures and can only be run on x64 architectures.
Resolved dependency errors
A version of a dependency does not exist, or it cannot be found. It may have been removed from the repository.
Call graph errors
These errors occur if pip or Poetry are unable to build the project because a required dependency cannot be located.