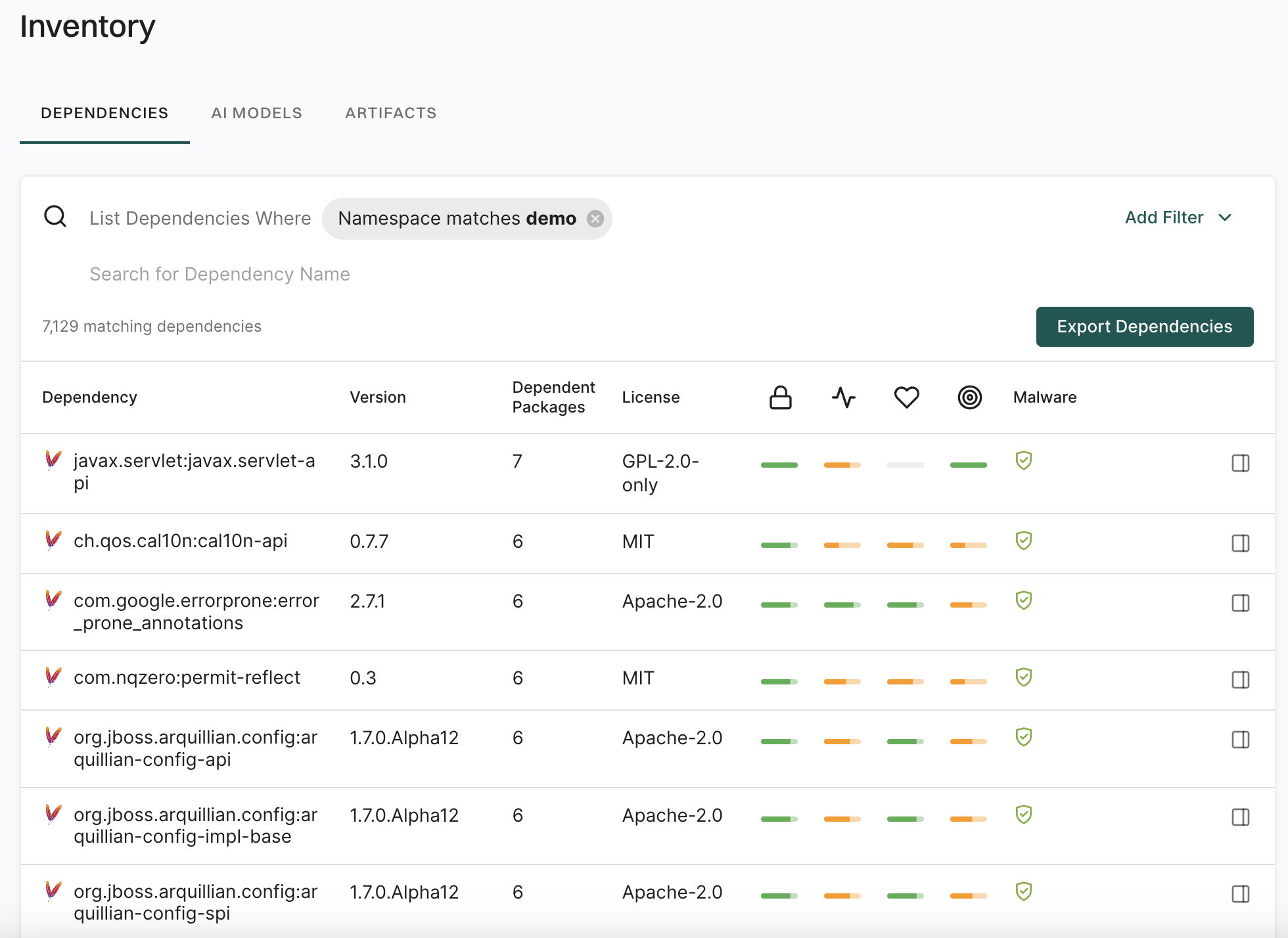
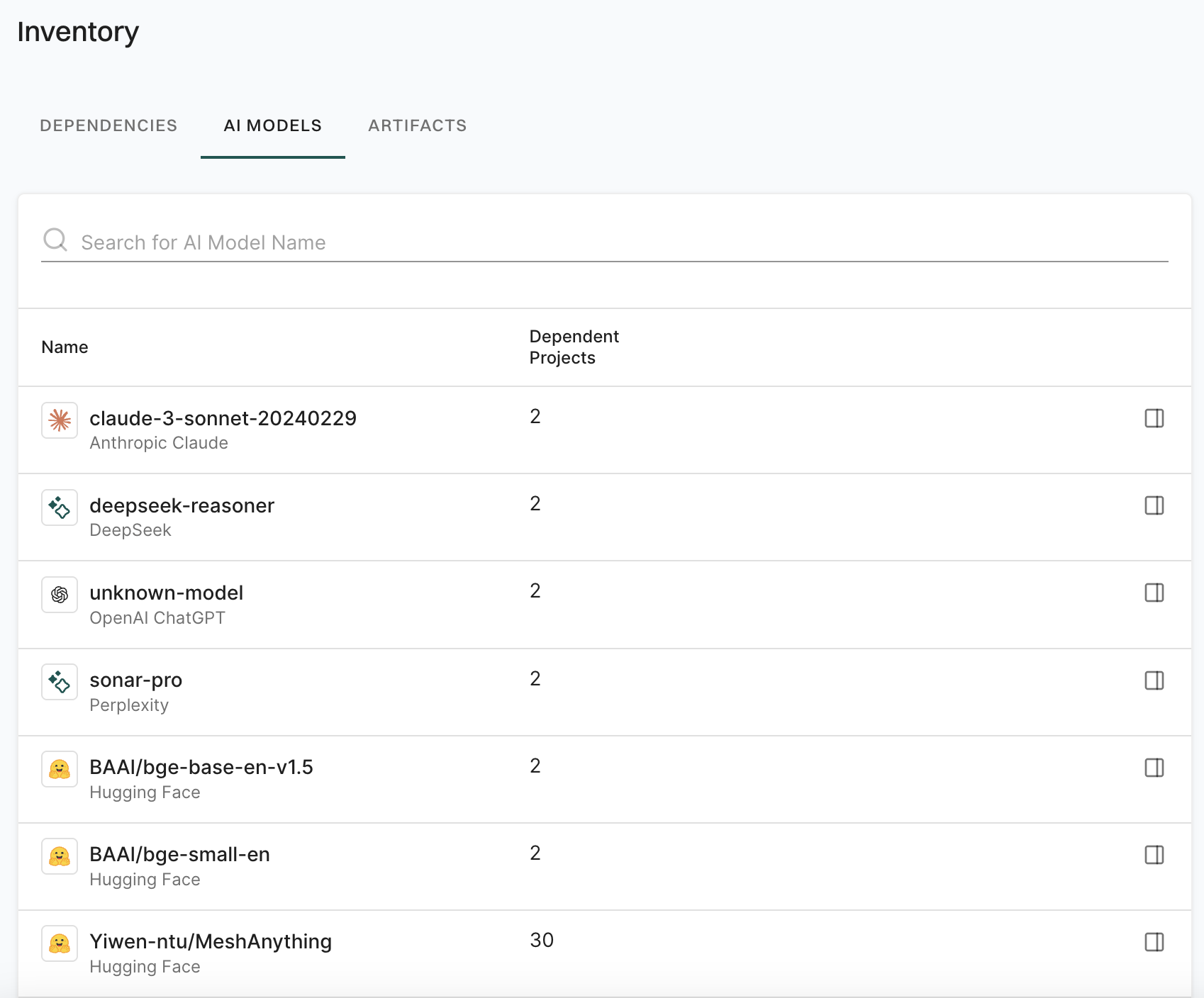
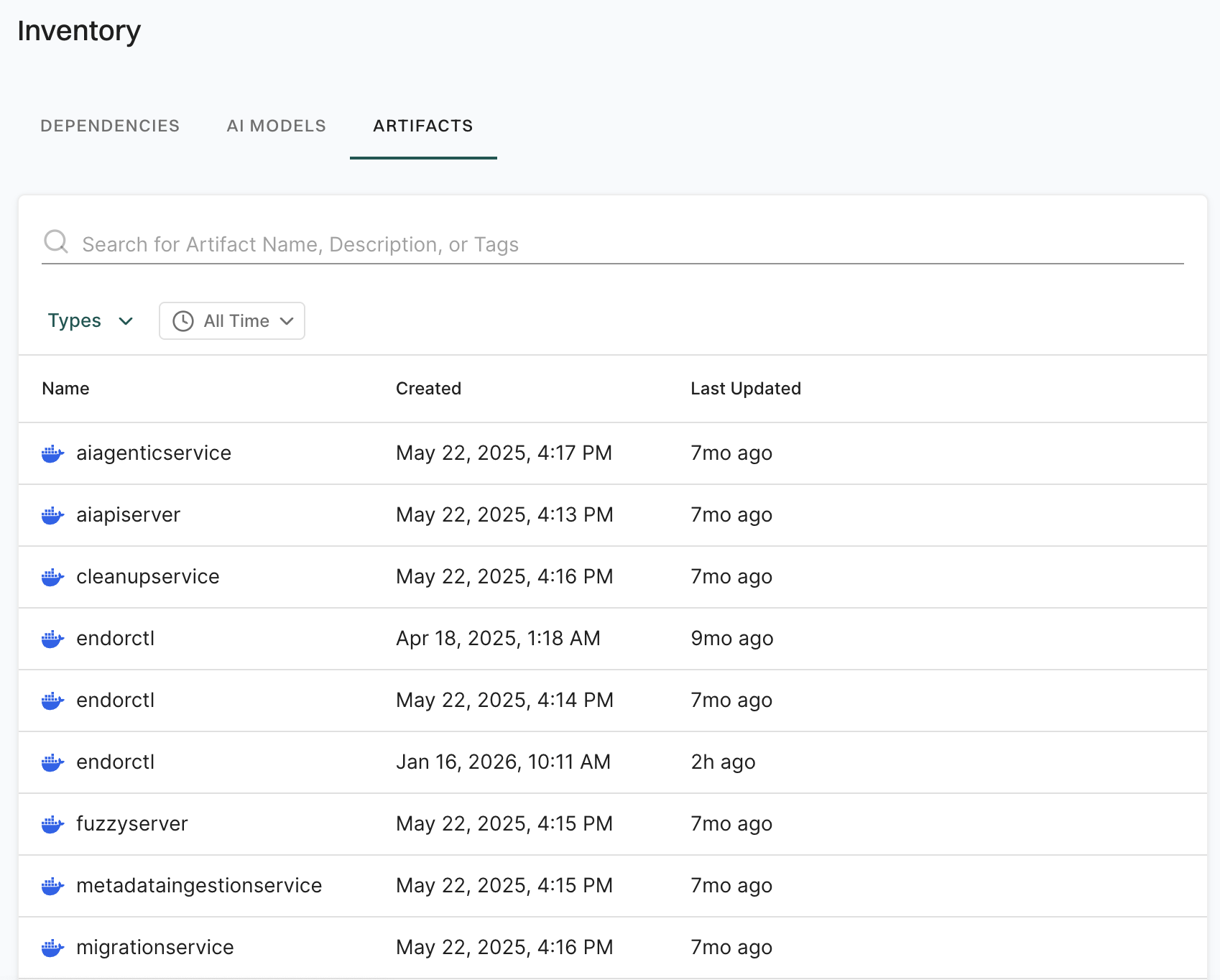
This guide provides instructions to set up and configure Endor Labs to get started with your first project scan. See Endor Labs user interface for more information on the user interface and various elements available in the interface.
Log in to Endor Labs
-
Visit https://app.endorlabs.com to access the login page.
-
You can sign in to Endor Labs with the following options:
- Google Workspace
- GitHub
- GitLab
- Email Link
- Supported enterprise SSO providers
-
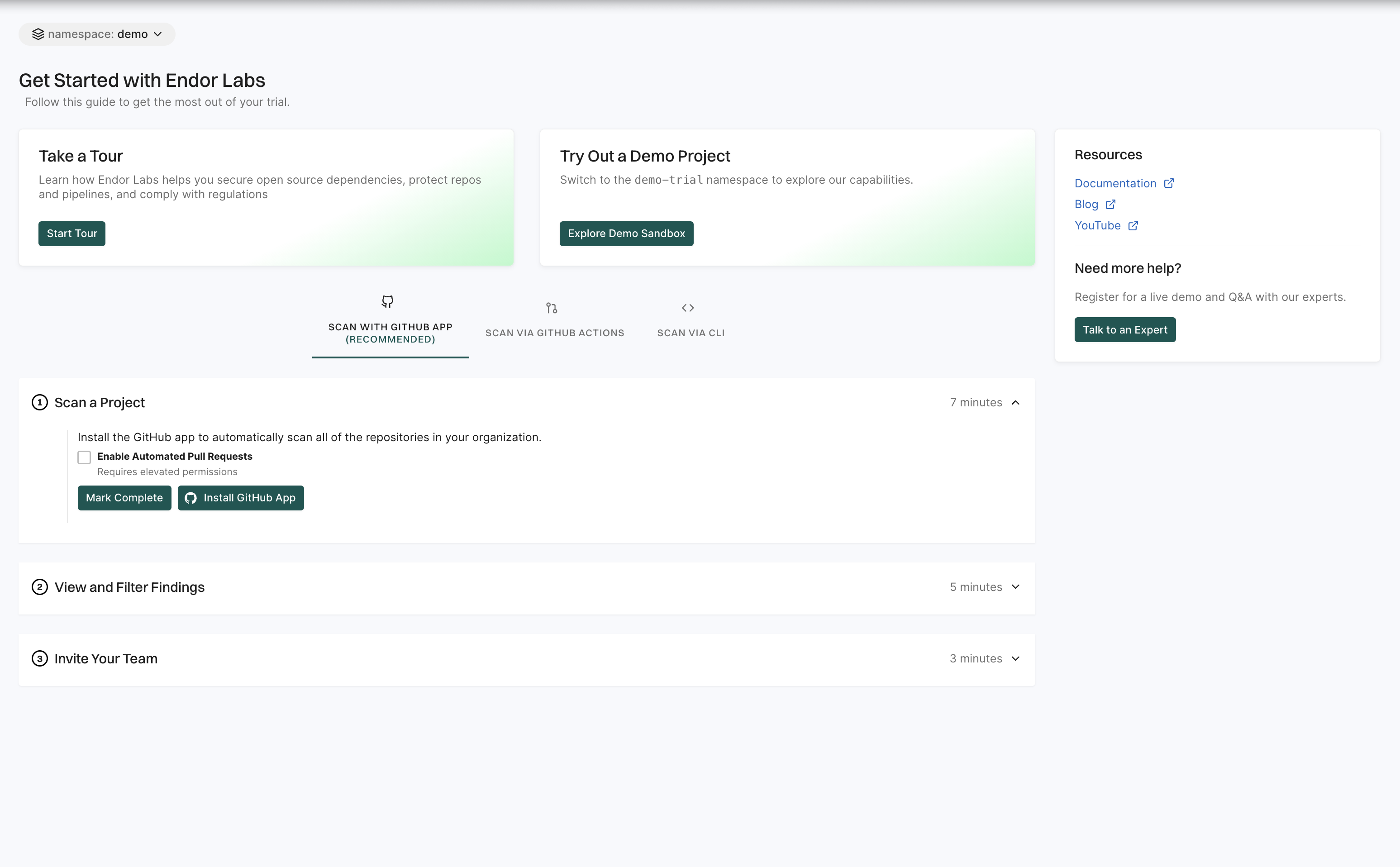
Select Get Started on the left sidebar to explore the available options.
- Select Start Tour to take a guided tour of the application and understand its main features.
- Select Explore Demo Sandbox to view Endor Labs capabilities and explore its features in a read-only tenant.
- Select SCAN WITH GitHub App to install the Endor Labs GitHub App.
- Select SCAN VIA GitHub Actions to scan a demo repository from GitHub and view findings.
- Select SCAN VIA CLI to set up your tenant and start scanning your repositories with the CLI.
-
See the quick start to set up with your first project scan.
Quick start
Log in to Endor Labs and select Get Started from the left sidebar to view the options.
You can choose from the following options:
You can also use GitHub Actions to scan demo projects.
Quick start with GitHub App
This guide provides instructions on how to get started with Endor Labs using the Endor Labs GitHub App. You can install the GitHub App or the GitHub App (Pro).
Prerequisites for GitHub App
Before installing and scanning projects with Endor Labs GitHub App, make sure you have:
- A GitHub cloud account and organization. If you don’t have one, create one at GitHub.
- Administrative permissions to your GitHub organization. Installing the Endor Labs GitHub App in your organization requires approval or permissions from your GitHub organizational administrator.
- Endor Labs GitHub App requires read permissions to Dependabot alerts, actions, administration, checks, code, commit statuses, issues, metadata, packages, pull requests, repository hooks, and security events. It does not need write access to any resources.
Set up the GitHub App with Endor Labs
-
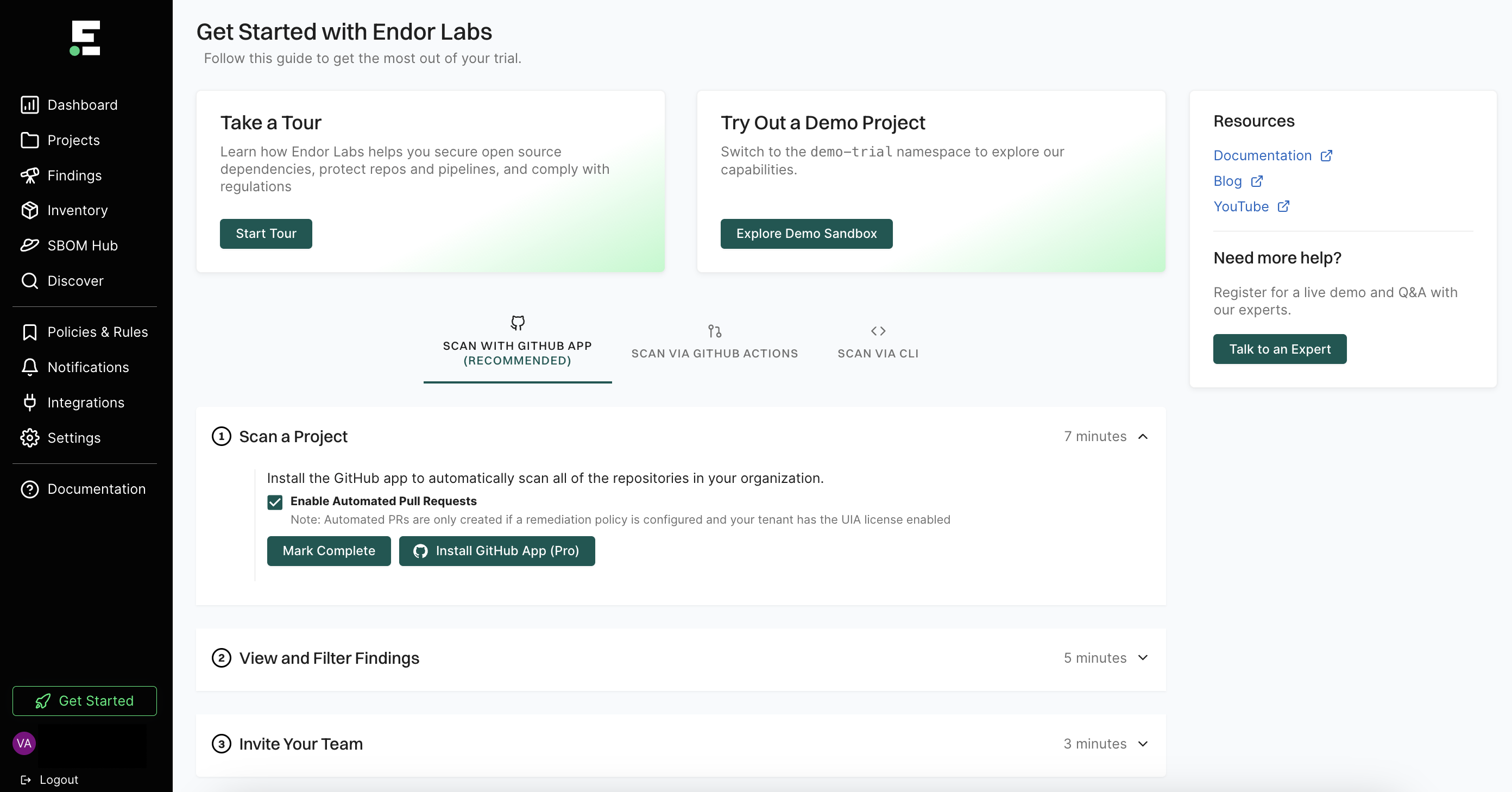
Sign in to Endor Labs and select Get Started from the left sidebar.
-
Select SCAN WITH GitHub App and click Install GitHub App Pro.
Deselect Enable Automated Pull Requests to disable automatic PR remediation and to install the GitHub App.
WarningYou can only install either the GitHub App or the GitHub App (Pro) in your environment.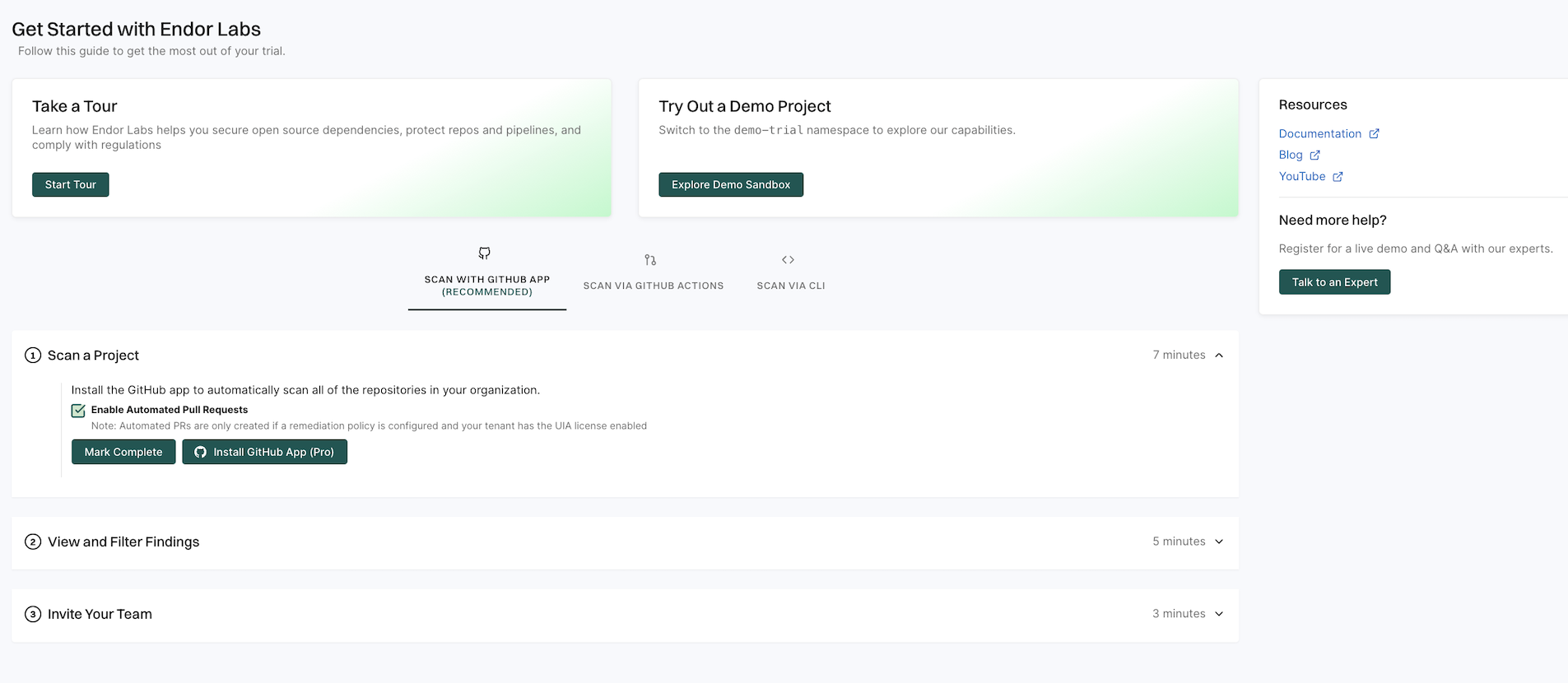
-
Choose the user and the organization where you wish to install the app.
-
Select whether to install and authorize Endor Labs on all your repositories or select the specific repositories that you wish to scan.
-
Click Install & Authorize.
NoteIf the button to install says Install and Request instead of Install and Authorize, you don’t have permission to install the app. Select Install and Request to notify your organizational administrator of your request.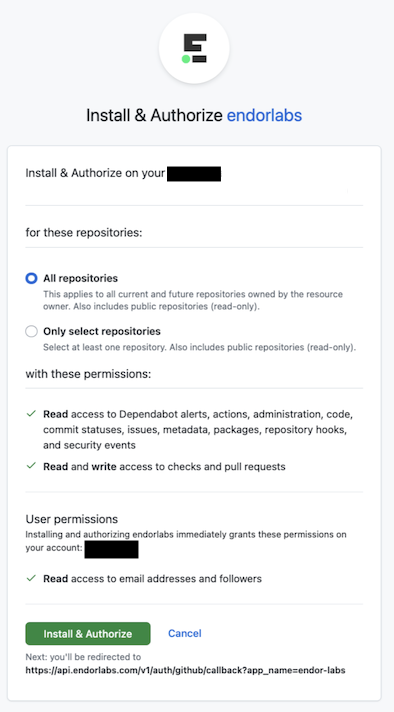
-
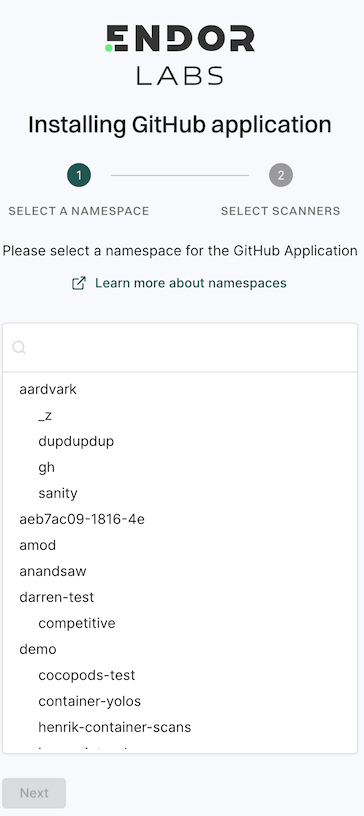
Select the Endor Labs namespace that you want to use and click Next.
-
Select the scan types to enable under SCANNERS.
The following scanners are available:
- SCA: Perform software composition analysis and discover AI models used in your repository.
- RSPM: Scan the repository for misconfigurations.
- Secret: Scan the repository for exposed secrets.
- CI/CD: Scan the repository and identify all the CI/CD tools used in the repository.
- SAST: Scan your source code for weakness and generate SAST findings.
-
Select Include Archived Repositories to scan your archived repositories. By default, the GitHub archived repositories aren’t scanned.
-
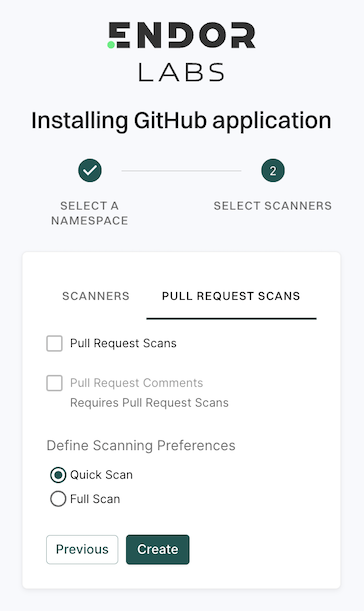
Select the PULL REQUEST SCANS to automatically scan the PRs submitted by users.
-
Select Pull Request Comments to enable GitHub Actions to comment on PRs for policy violations.
-
In Define Scanning Preferences, select either:
-
Quick Scan to gain rapid visibility into your software composition. It performs dependency resolution but does not conduct reachability analysis to prioritize vulnerabilities. The quick scan enables users to swiftly identify potential vulnerabilities in dependencies, ensuring a smoother and more secure merge into the main branch.
-
Full Scan to perform dependency resolution, reachability analysis, and generate call graphs for supported languages and ecosystems. This scan enables users to get complete visibility and identifies all issues dependencies, call graph generation before merging into the main branch. Full scans may take longer to complete, potentially delaying PR merges.
See GitHub scan options for more information on the scans that you can do with the GitHub App.
-
-
-
Click Create.
You will be redirected back to Endor Labs.
After installation, Endor Labs scans your repositories and generates findings. Subsequently, Endor Labs scans your repository every 24 hours. See Findings for more information on the findings generated by the scans.
To review the scan results, see Review the results of your project.
Quick start with endorctl
This guide provides step-by-step instructions to set up and configure an Endor Labs tenant while getting started with your first project scan in your local system.
Use the following steps to scan your first project with Endor Labs:
- Install Endor Labs on your local system
- Authenticate to Endor Labs
- Clone your repository
- Scan your first project
- Review your results
Install endorctl
Use one of the following methods to install endorctl on your local system.
Install with Homebrew (macOS/Linux)
brew tap endorlabs/tap
brew install endorctlInstall with npm (macOS/Linux/Windows)
npm install -g endorctlDownload binary directly
curl https://api.endorlabs.com/download/latest/endorctl_linux_amd64 -o endorctl
echo "$(curl -s https://api.endorlabs.com/sha/latest/endorctl_linux_amd64) endorctl" | sha256sum -c
chmod +x ./endorctlcurl https://api.endorlabs.com/download/latest/endorctl_macos_arm64 -o endorctl
echo "$(curl -s https://api.endorlabs.com/sha/latest/endorctl_macos_arm64) endorctl" | shasum -a 256 -c
chmod +x ./endorctlcurl -O https://api.endorlabs.com/download/latest/endorctl_windows_amd64.exe
ren endorctl_windows_amd64.exe endorctl.exeFor more details, see Install and configure endorctl.
Authenticate to Endor Labs
To authenticate your client with Endor Labs, utilize the built-in command endorctl init along with an external identity provider. Endor Labs supports multiple identity providers, including Google, GitHub, GitLab, Email link authentication, and Custom Identity Provider through Enterprise SSO.
endorctl init --auth-mode=google
endorctl init --auth-mode=github
endorctl init --auth-mode=gitlab
endorctl init --auth-email=<insert_email_address>
endorctl init --auth-mode=sso --auth-tenant=<insert-your-tenant>
For more information, see Install and configure endorctl.
Clone your repository
Upon successful authentication to Endor Labs using endorctl, proceed to clone the repository you intend to scan. If you prefer initiating with a dummy app for scanning, feel free to skip to the next step.
To clone a Git repository, use the git clone command followed by the clone link of the repository. You can find the URL on the repository’s page on a platform like GitHub or GitLab. For example,
git clone https://github.com/username/repo-name.git
Replace https://github.com/username/repo-name.git with the actual URL of the Git repository you want to clone.
Navigate to the repository you’ve cloned.
cd <repo-name>
Run your first scan
Endor Labs supports three distinct scan types. See each section for instructions on how to run each scan type with Endor Labs.
Scan for OSS risk
Follow these steps to scan with Endor Labs for open source risk:
- Install software prerequisites
- Clone your repository
- Build your software
- Scan with Endor Labs for OSS risk
endorctl to learn how to perform a scan.
Install software prerequisites
The following prerequisites must be met to scan with Endor Labs for OSS risk:
- A local installation of Git or the ability to clone repositories in CI. See the Git documentation for instructions on installing Git
- A runtime environment and build tools for supported software development languages your team uses must be installed on any system used for testing. For more information, see Supported languages and frameworks.
For more information on supported languages, package managers and build systems and the requirements for each language, see their respective page.
| Language | Package Managers / Build Tools | Manifest files | Runtime Requirements |
|---|---|---|---|
| Java | Maven | pom.xml |
JDK version 11-25; Maven 3.6.1 and higher versions |
| Gradle | build.gradle |
JDK version 11-25; Gradle 6.0.0 and higher versions | |
| Bazel | workspace, MODULE.bazel, BUILD.bazel |
JDK version 11-25; Bazel versions 5.x.x, 6.x.x, and 7.x.x |
|
| Kotlin | Maven | pom.xml |
JDK version 11-25; Maven 3.6.1 and higher versions |
| Gradle | build.gradle |
JDK version 11-25; Gradle 6.0.0 and higher versions | |
| Golang | Go | go.mod, go.sum |
Go 1.12 and higher versions |
| Bazel | workspace, MODULE.bazel, BUILD.bazel |
Bazel versions 5.x.x, 6.x.x, and 7.x.x |
|
| Rust | Cargo | cargo.toml, cargo.lock |
Rust 1.63.0 and higher versions |
| JavaScript | npm | package-lock.json, package.json |
npm 6.14.18 and higher versions |
| TypeScript | npm | package-lock.json, package.json |
npm 6.14.18 and higher versions |
| Yarn | yarn.lock, package.json |
Yarn all versions | |
| Rush | rush.json, package.json; lock file in common/config/rush/ |
Rush (version in rush.json); set ENDOR_RUSH_ENABLED=true | |
| Python | pip | requirements.txt |
Python 3.6 and higher versions; pip 10.0.0 and higher versions |
| Poetry | pyproject.toml, poetry.lock |
||
| PDM | pyproject.toml, pdm.lock |
||
| UV | pyproject.toml, uv.lock |
||
| PyPI | setup.py, setup.cfg, pyproject.toml |
||
| Bazel | workspace, MODULE.bazel |
Bazel versions 5.x.x, 6.x.x, and 7.x.x |
|
| .NET (C#) | NuGet | *.csproj, package.lock.json, projects.assets.json, Directory.Build.props, Directory.Packages.props, *.props |
.NET 5.0 and higher versions; .NET Core 1.0 and higher versions; .NET Framework 4.5 and higher versions. Call graphs are supported for .NET 7.0.1 and higher versions. |
| Scala | sbt | build.sbt |
sbt 1.3 and higher versions |
| Gradle | build.gradle, build.gradle.kts |
JDK version 11-25; Gradle 6.0.0 and higher versions | |
| Ruby | Bundler | Gemfile, *.gemspec, gemfile.lock |
Ruby 2.6 and higher versions |
| Swift/Objective-C | CocoaPods | Podfile, Podfile.lock |
CocoaPods 0.9.0 and higher versions |
| SwiftPM | Package.swift |
SwiftPM 5.0.0 and higher versions | |
| PHP | Composer | composer.json, composer.lock |
PHP 5.3.2 and higher versions; Composer 2.2.0 and higher versions |
For more information, see endorctl commands and working with the API.
Build your software
To run a complete and accurate scan with Endor Labs, ensure that the software can be successfully built, incorporating well-formatted manifest files. To maximize the benefits of an Endor Labs OSS scan, you should perform a comprehensive testing as a post-build step, either locally or in a CI pipeline. Use the following commands to verify that the software can be built successfully with well-formatted manifest files before initiating the scan.
mvn dependency:tree
mvn clean install
gradle dependencies --configuration runtimeClasspath
./gradlew assemble
# Use `gradle assemble` if you do not have a gradle wrapper in your repository
npm install
yarn install
export ENDOR_PNPM_ENABLED=true
pnpm install
export ENDOR_RUSH_ENABLED=true
rush install
dotnet restore
dotnet build
composer install
go mod tidy
python3 -m venv venv
source venv/bin/activate
venv/bin/python3 -m pip install
poetry install
bundler install
pod install
sbt projects
sbt compile
sbt dependencyTree
gradle dependencies --configuration runtimeClasspath
./gradlew assemble
# Use `gradle assemble` if you do not have a gradle wrapper in your repository
cargo build
Scan your project for OSS risk
To scan and monitor all packages in a given repository from the root of the repository, run the following command:
endorctl scan
If your project contains multiple programming languages, you can specify them as a comma-separated list using the --languages flag:
endorctl scan --languages=<languages-list>
Where <languages-list> should be provided as a comma-separated list from the supported languages: c,c#,go,java,javascript,kotlin,php,python,ruby,rust,scala,swift,typescript,swifturl.
Scanning an example repository
To scan an example repository https://github.com/OWASP-Benchmark/BenchmarkJava.git, you must perform the following steps after successfully authenticating to Endor Labs:
-
Clone the repository
https://github.com/OWASP-Benchmark/BenchmarkJava.gitgit clone https://github.com/OWASP-Benchmark/BenchmarkJava.git -
Navigate to the repository on your local system
cd BenchmarkJava -
Build the repositories package with Maven:
mvn clean install -
Scan the repository
endorctl scan
Scanning for leaked secrets
The following procedure should be used to scan with Endor Labs for potential secrets leaked into your source code.
To scan for all potentially leaked secrets in the checked out branch of your repository, run the following command:
endorctl scan --secrets
Often, secrets are leaked outside the context of your repositories main branch and can be found in older branches or those that are under active development. To identify these, Endor Labs inspects the Git logs of the repository.
To scan for all potentially leaked secrets in all branches of your repository, run the following command:
endorctl scan --secrets --git-logs
Scan for GitHub misconfigurations
Endor Labs allows teams to scan their repository for configuration best practices in alignment with organizational policy.
Prerequisites
To scan the GitHub repository, you must have:
- The GitHub repository HTTPS clone URL
- A personal access token with access administrative access to the repository. For help creating a personal access token see GitHub documentation.
If you are on a self-hosted GitHub Enterprise Server, you should also have:
- The GitHub API URL (This is typically the FQDN of the GitHub server)
- A local copy of the CA Certificate if the certificate is self-signed or from a private CA
Running a misconfiguration scan
To scan a GitHub repository for misconfigurations:
-
Export your personal access token as an environment variable:
export GITHUB_TOKEN=<personal_access_token> -
Scan the repository to retrieve configuration information and analyze the configuration against organizational policy or configuration best practices:
endorctl scan --repository-http-clone-url=https://github.com/<organization>/<repository>.git --github
For source control systems on the GitHub Enterprise Server, you must set the --github-api-url flag to your GitHub Enterprise server domain name:
endorctl scan --github-api-url=https://<fully_qualified_domain_name_to_GitHub_Enterprise_Server> --repository-http-clone-url=https://<fully_qualified_domain_name_to_GitHub_Enterprise_Server>/<organization>/<repository>.git --github
Review the results of your project
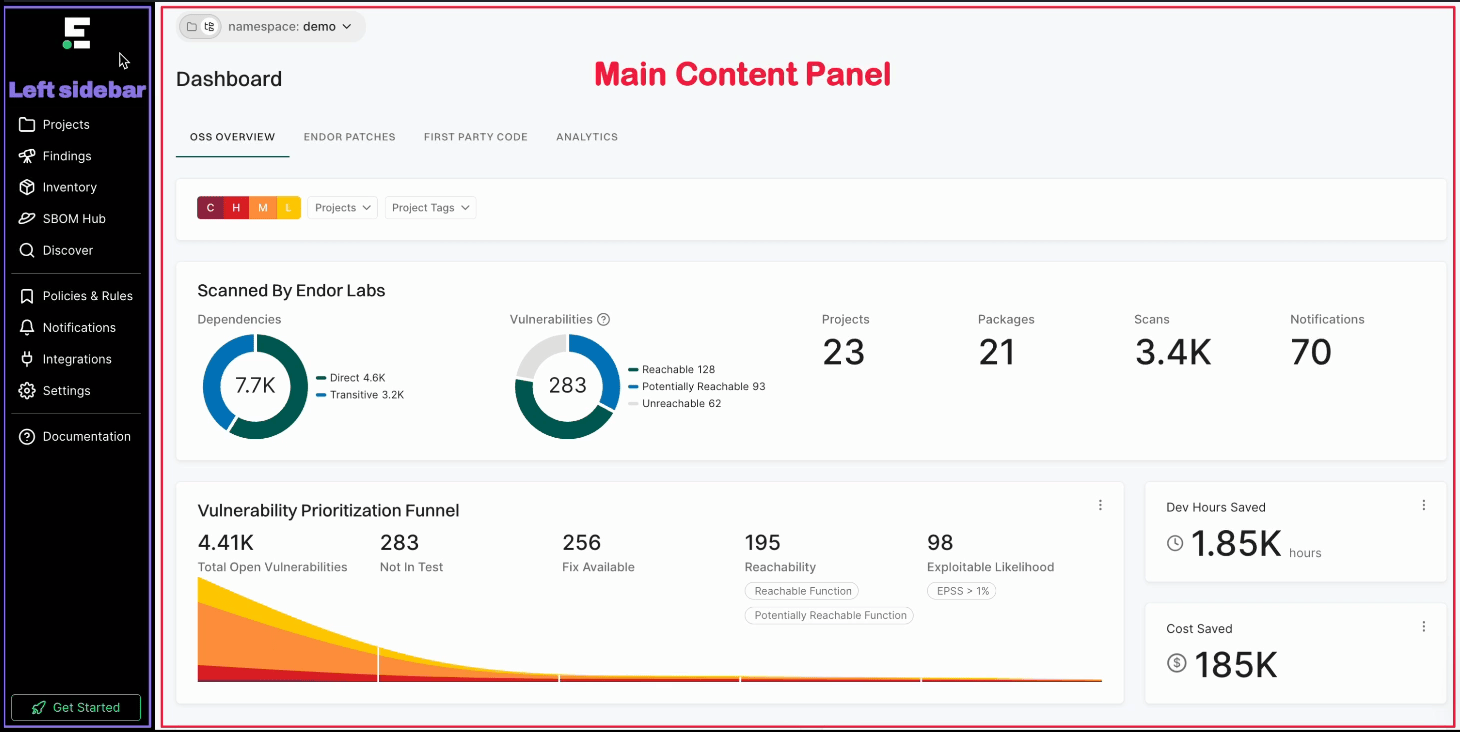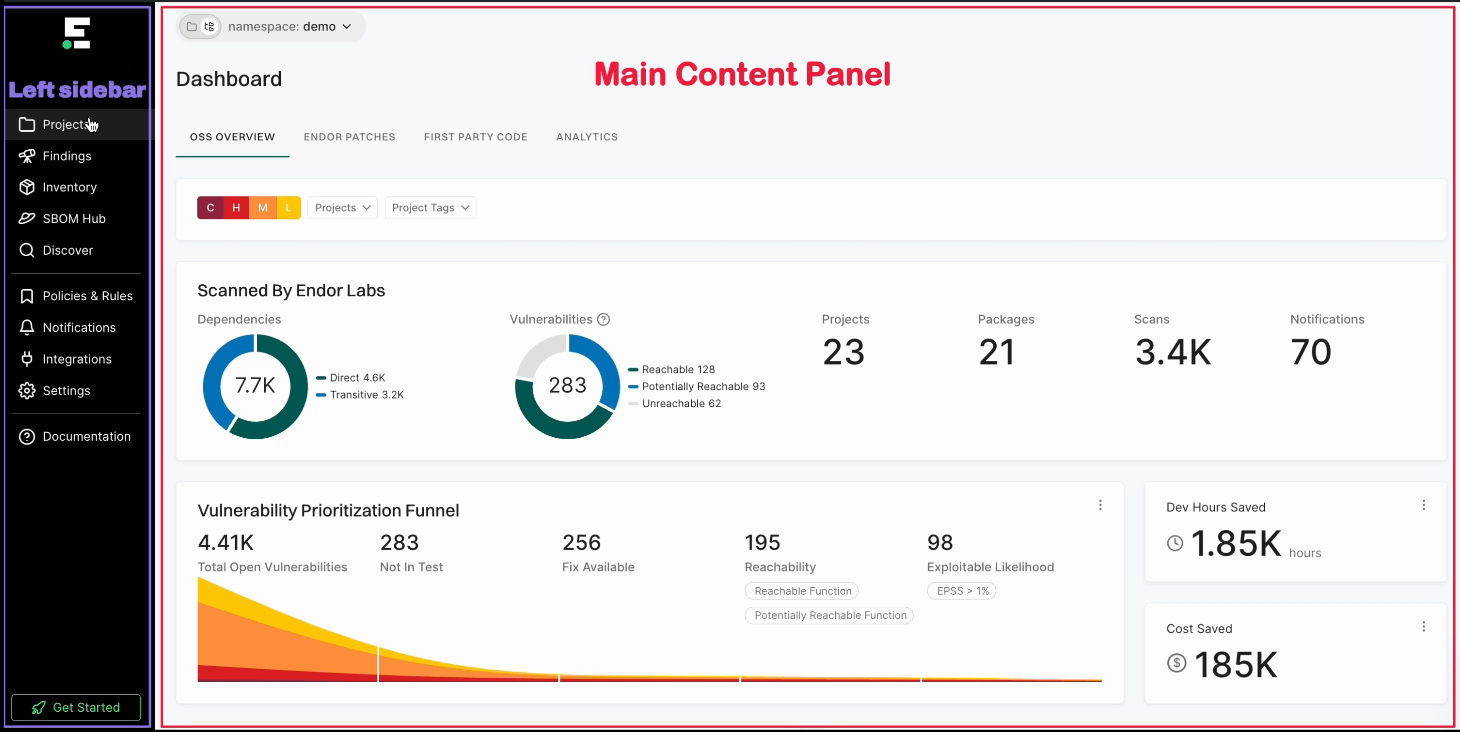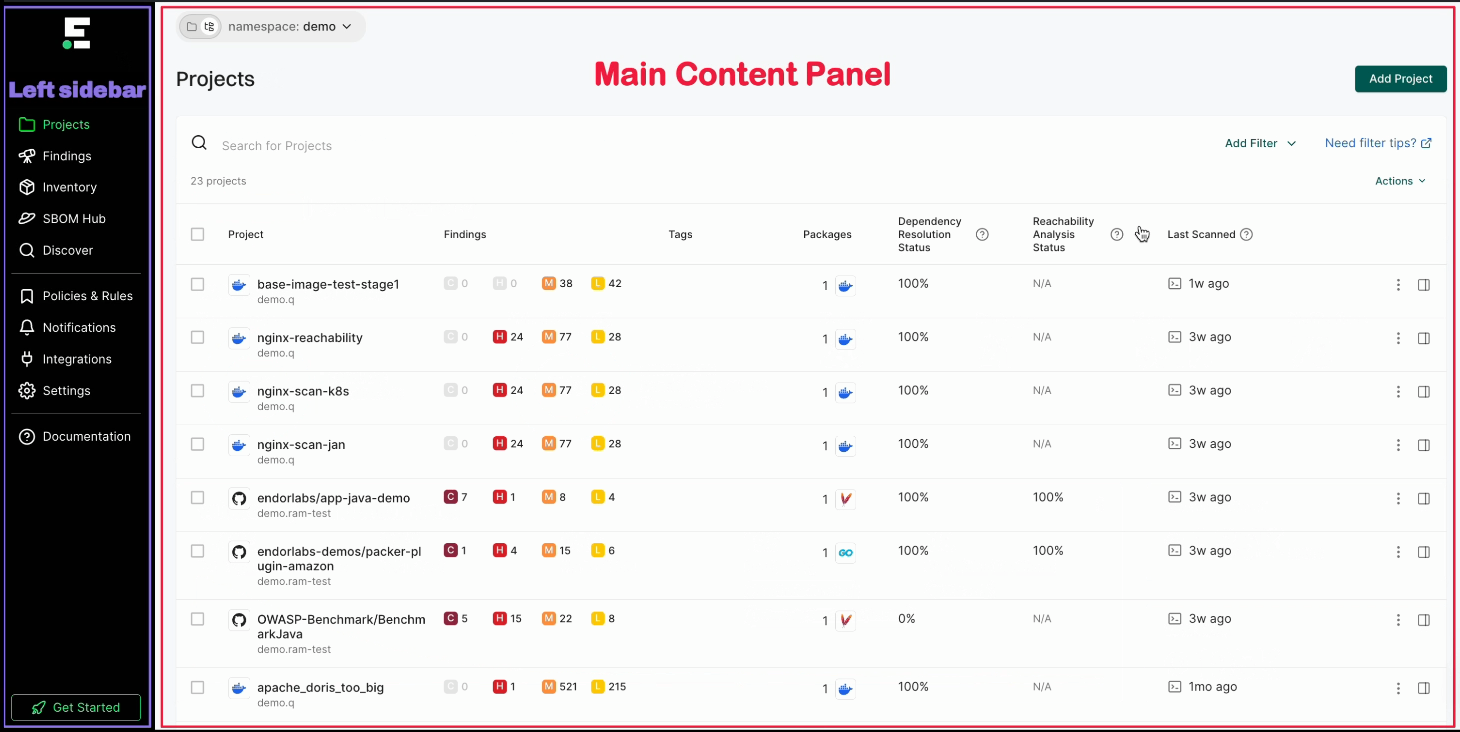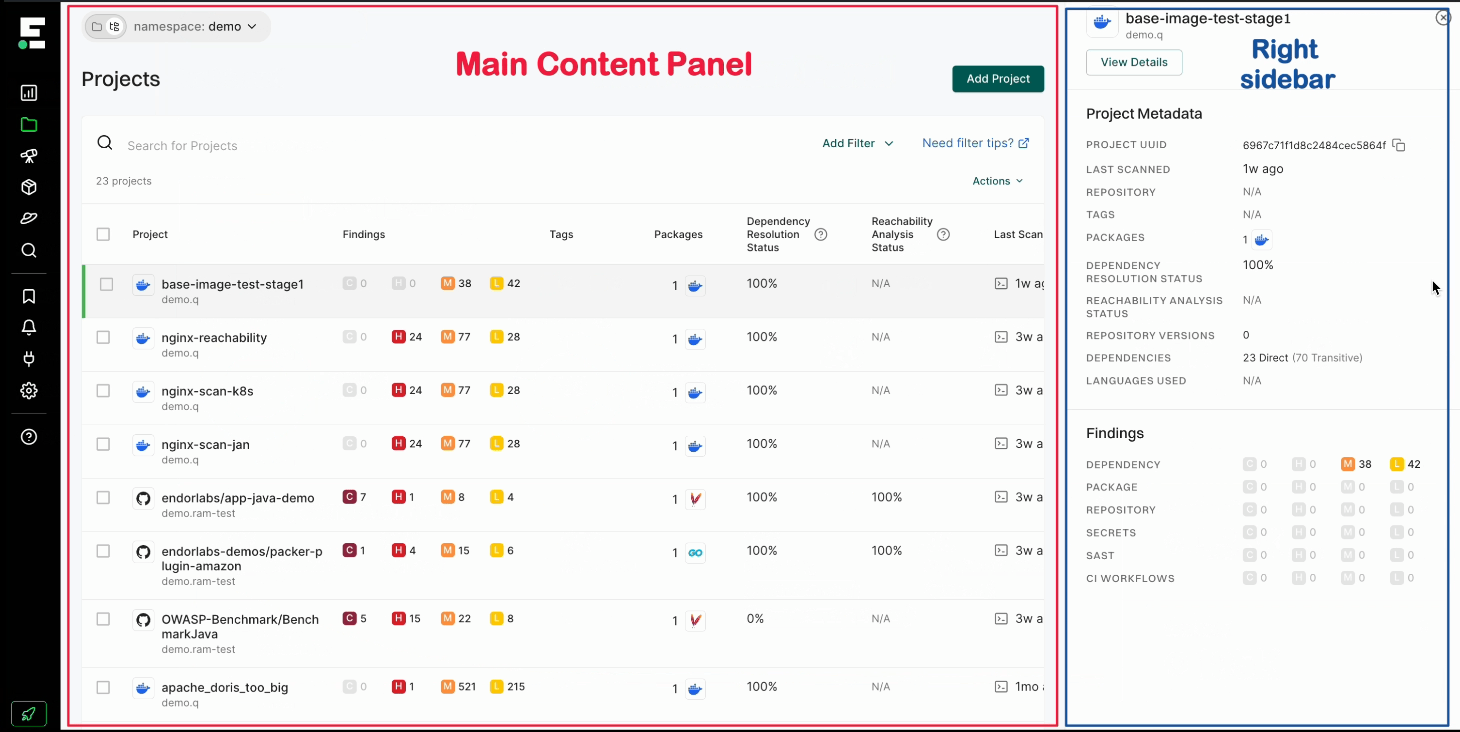
-
Sign in to the Endor Labs user interface, click Projects on the left sidebar.
-
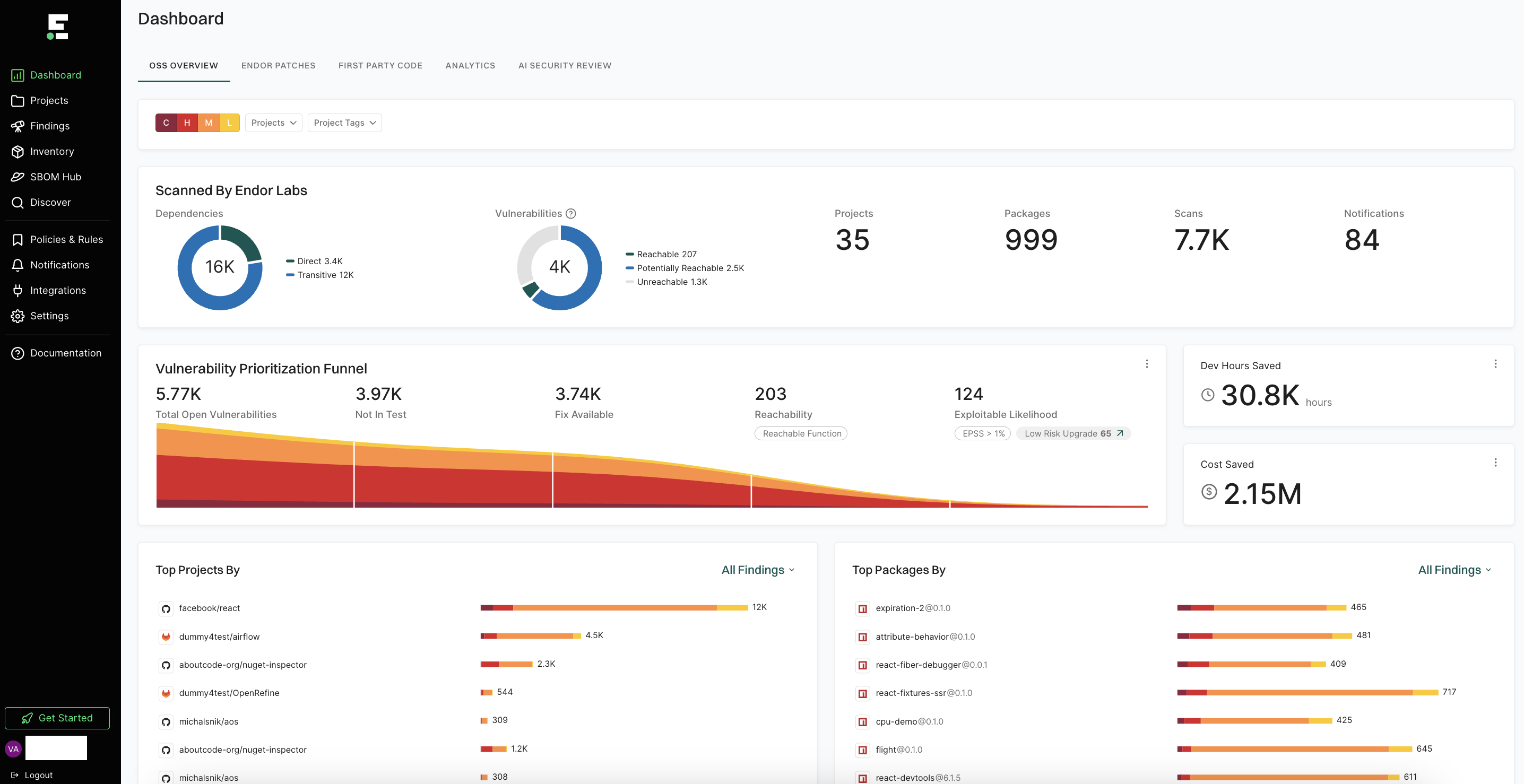
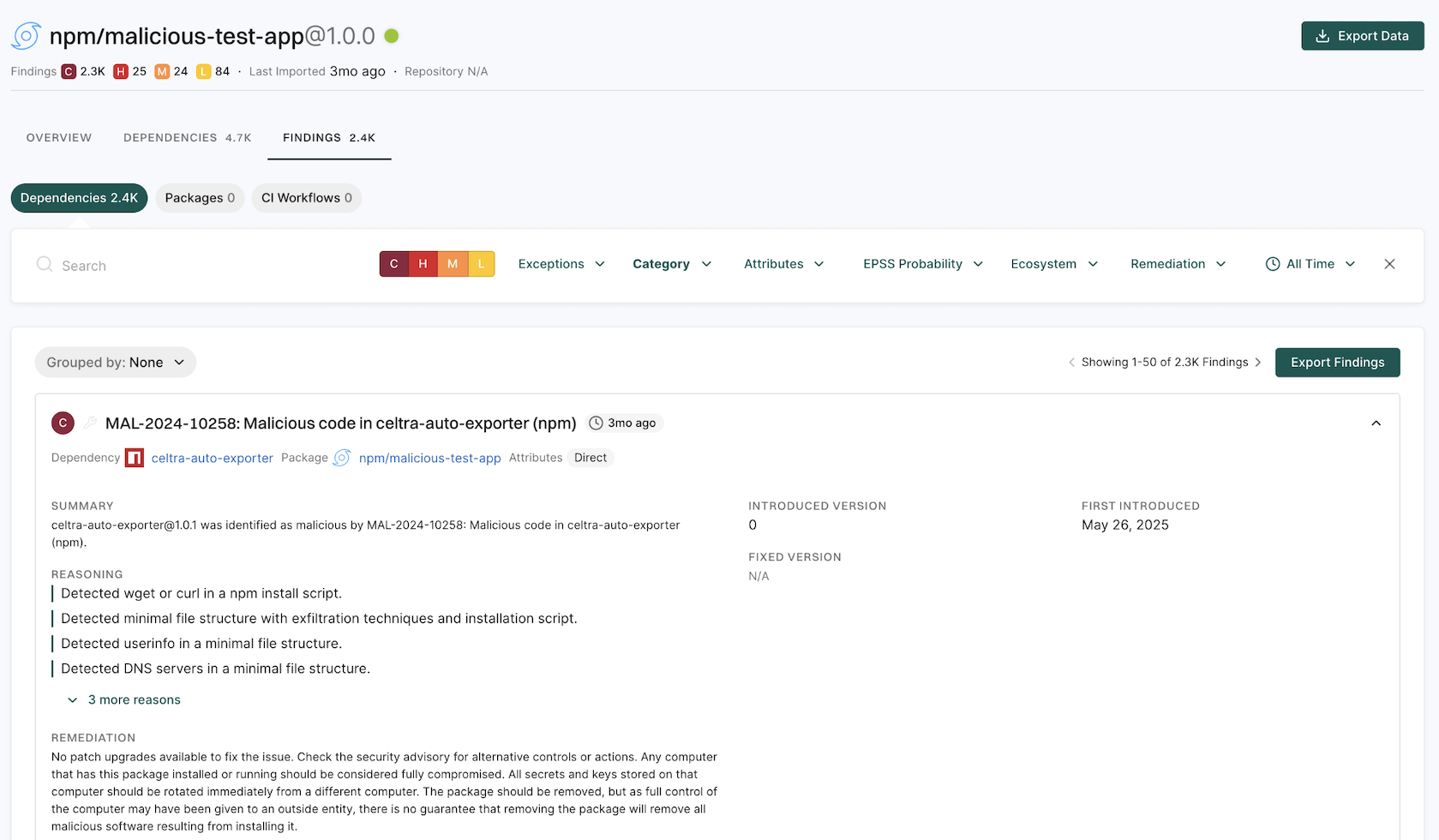
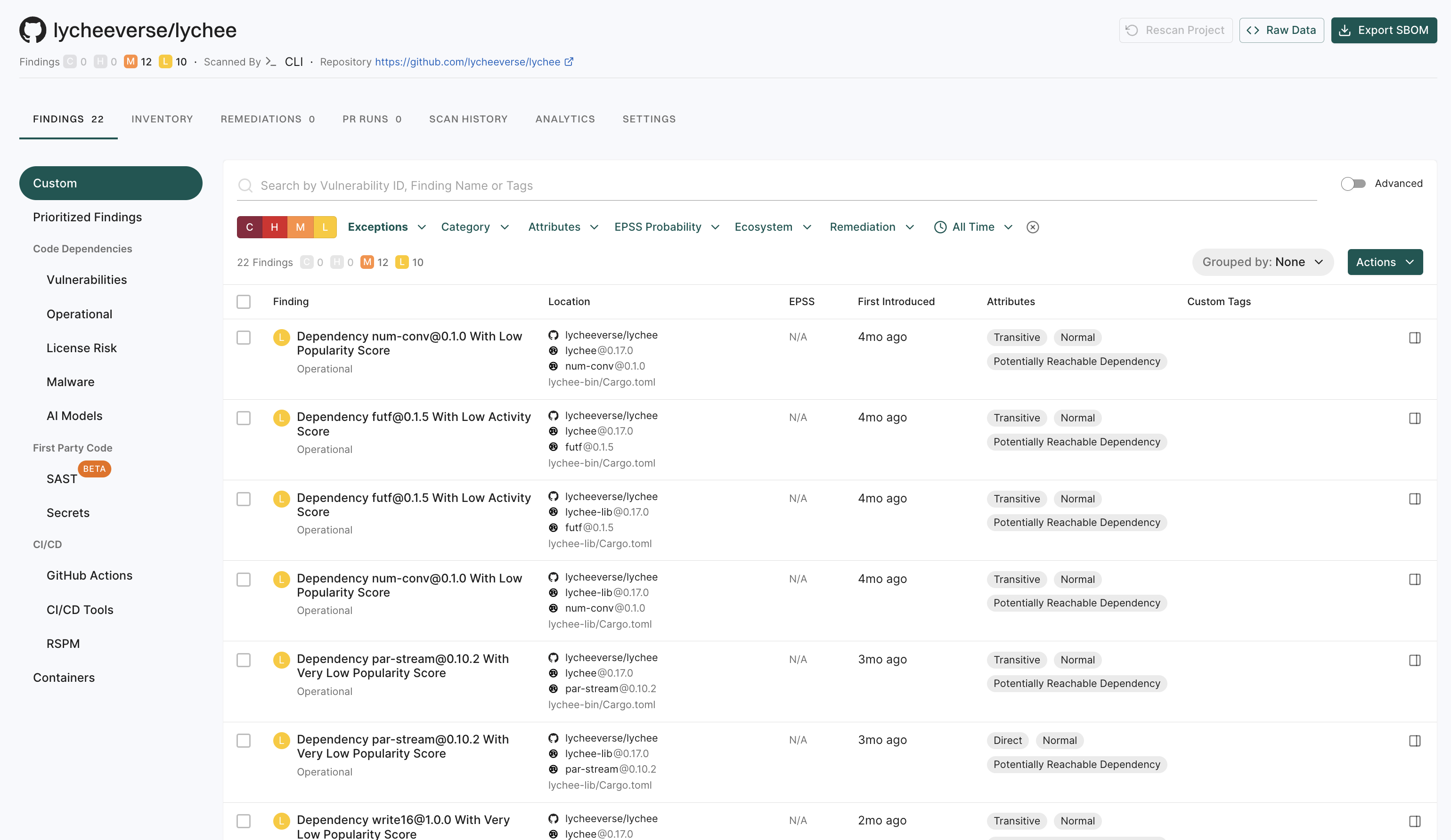
The Findings section provides a summary of vulnerabilities found in each project, categorized by severity:
- C: Critical
- H: High
- M: Medium
- L: Low
-
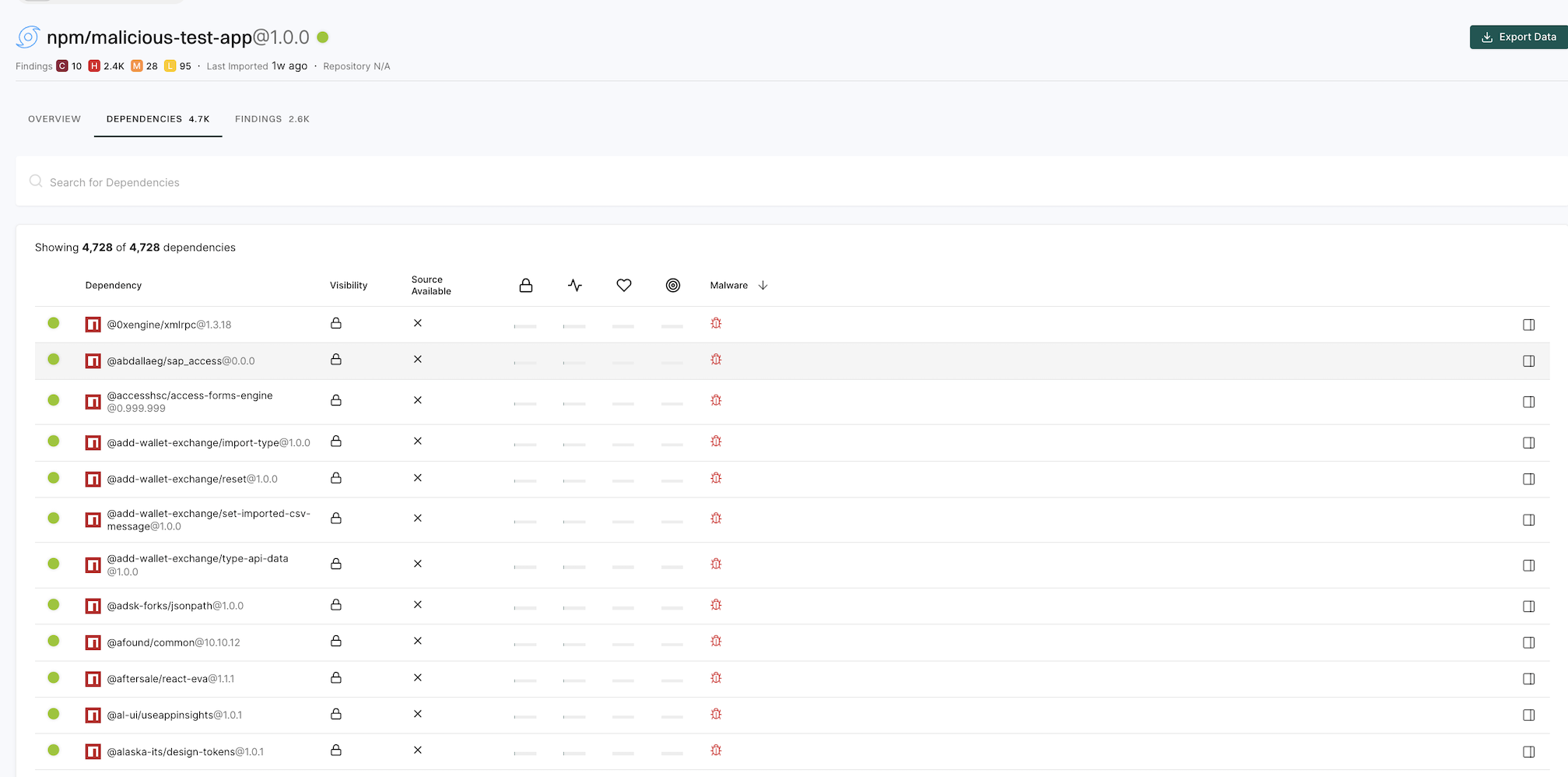
Under Packages, the number indicates the identified packages. Click on the icon next to the number to open a right sidebar containing the following details :
- Project metadata: Information such as UUID, repository details, dependencies, and repository versions.
- Findings: A breakdown of the detected vulnerabilities categorized by dependency, package, repository, secrets, and CI workflows.
- Tools used during analysis: A list of tools involved in the scanning process.
-
Select your project to view its details. See Findings for more information.
Next steps
- Explore the Endor Labs user interface to learn how to navigate through the platform.