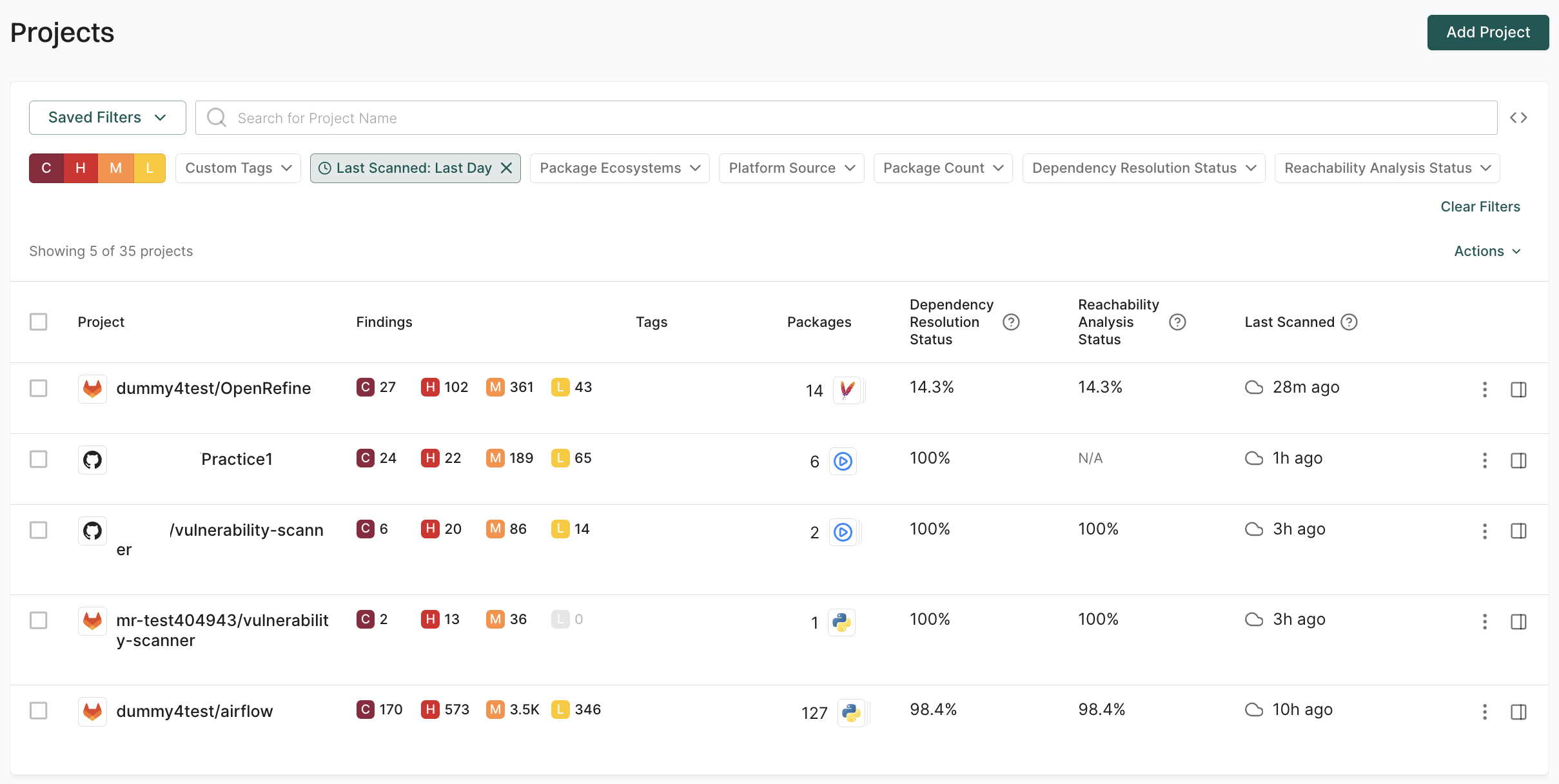
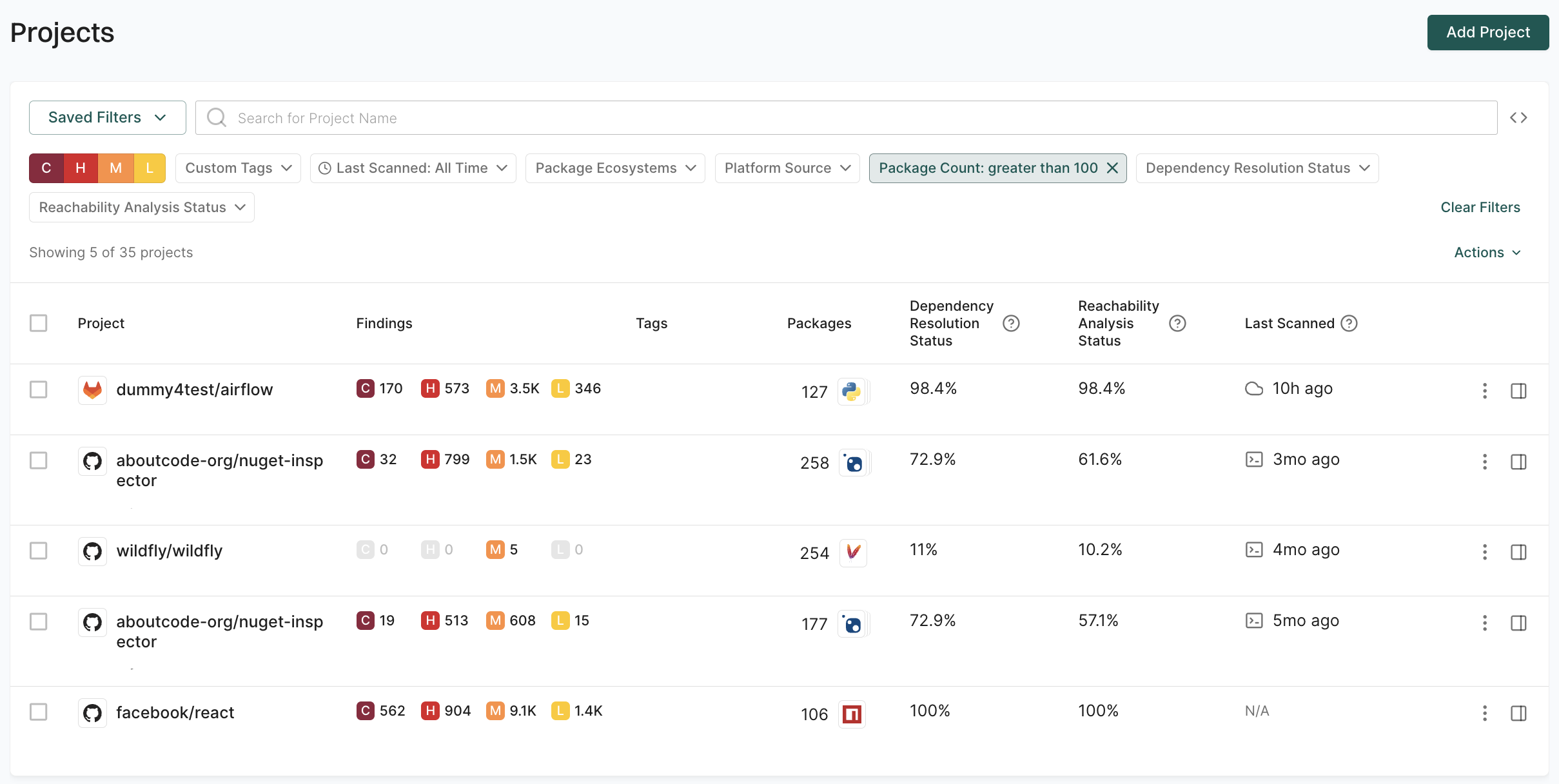
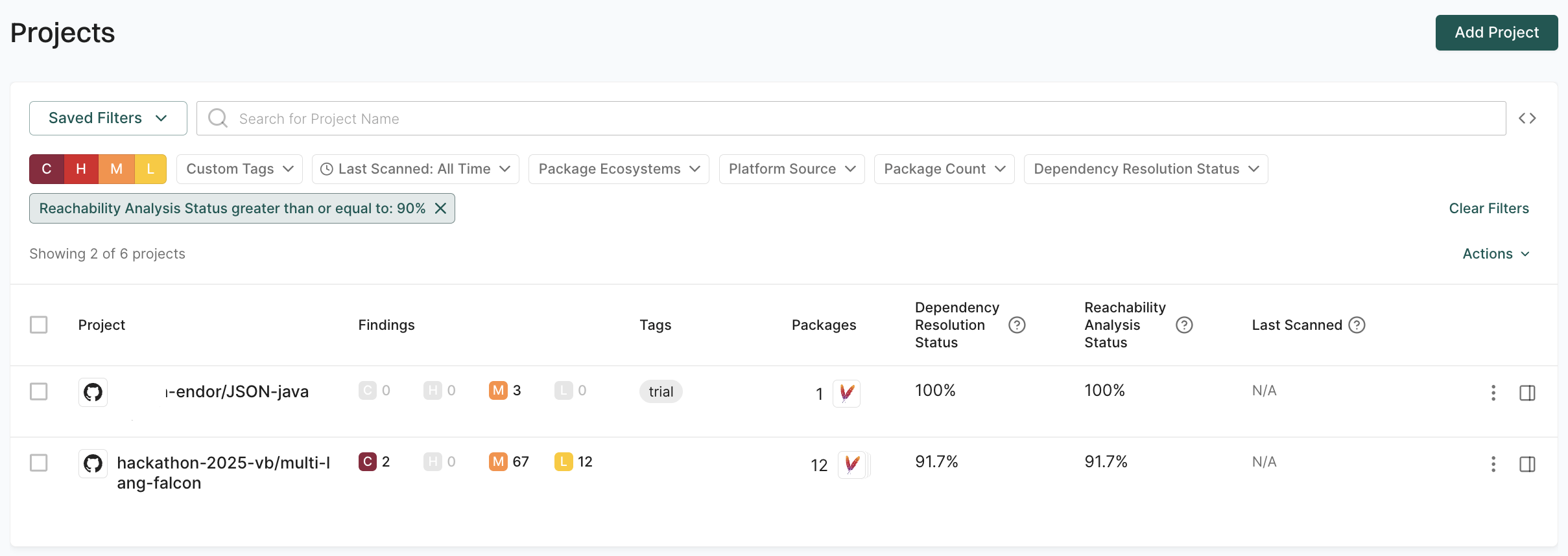
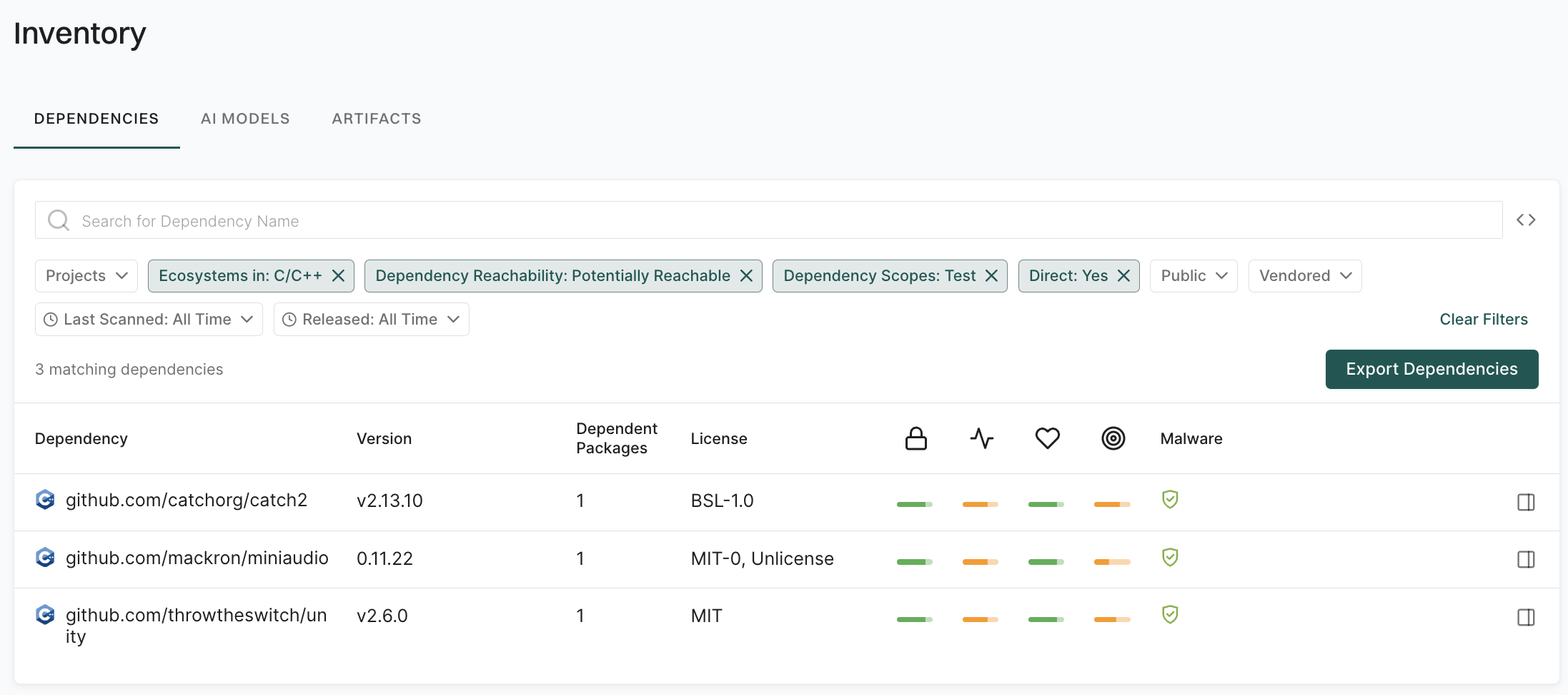
Explore how to effectively use Endor Labs to scan different branches within your organization’s software development workflows. Properly managing branches and integrating robust scanning processes is crucial for maintaining code quality, security, and consistency across your development pipeline.
This guide provides actionable insights and strategies for setting up Endor Labs to seamlessly scan and monitor your branches, ensuring that potential issues are detected and addressed early in the development cycle.
A typical Git Flow may include the following types of branches:
maindevelopreleasefeaturehotfix
The two primary branches in Git Flow are main and develop. The main or the develop branch stores the official release history and often serves as the integration branch for features. The feature, release, and hotfix branches can serve as supporting branches with different intended purposes.
Baseline branch
A baseline branch is any branch that falls into one of the following categories:
- A branch used to maintain release history or as a single source of truth
- A branch used for managing releases
- A branch serving as a source of integration for features and bug fixes
In the Git flow model, main, release, and develop can serve as the baseline branch.
The main branch is typically the primary branch and is often chosen as the default branch in a Git repository. It serves as the central integration point for all development efforts and usually contains the most stable and up-to-date version of the codebase, reflecting the latest approved changes that are ready for production or further testing. This is why we recommend using main not only as the baseline branch but also as the default branch for repositories. Endor Labs uses metrics from the default branch as the primary context for displaying statistics and metrics on the dashboards.
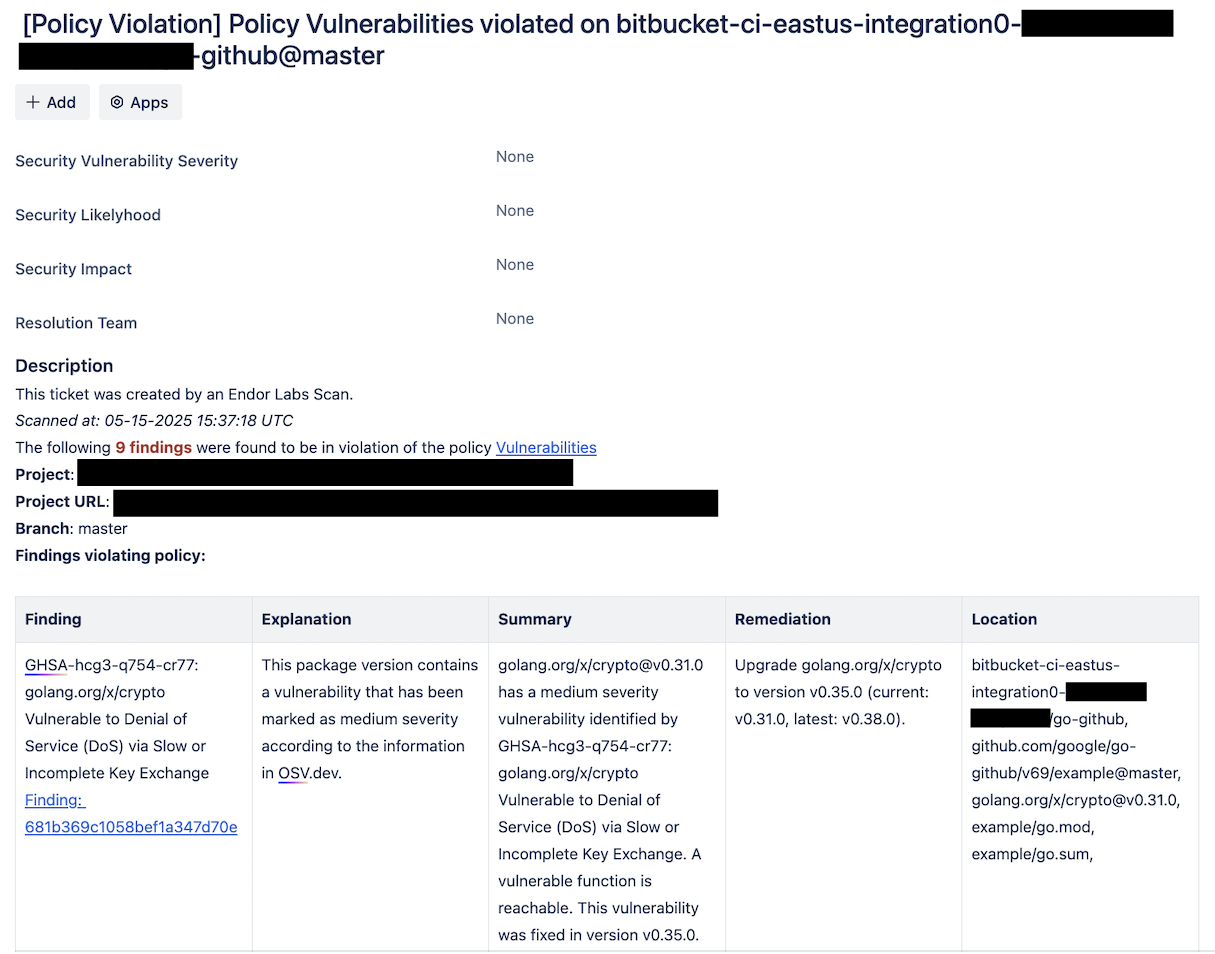
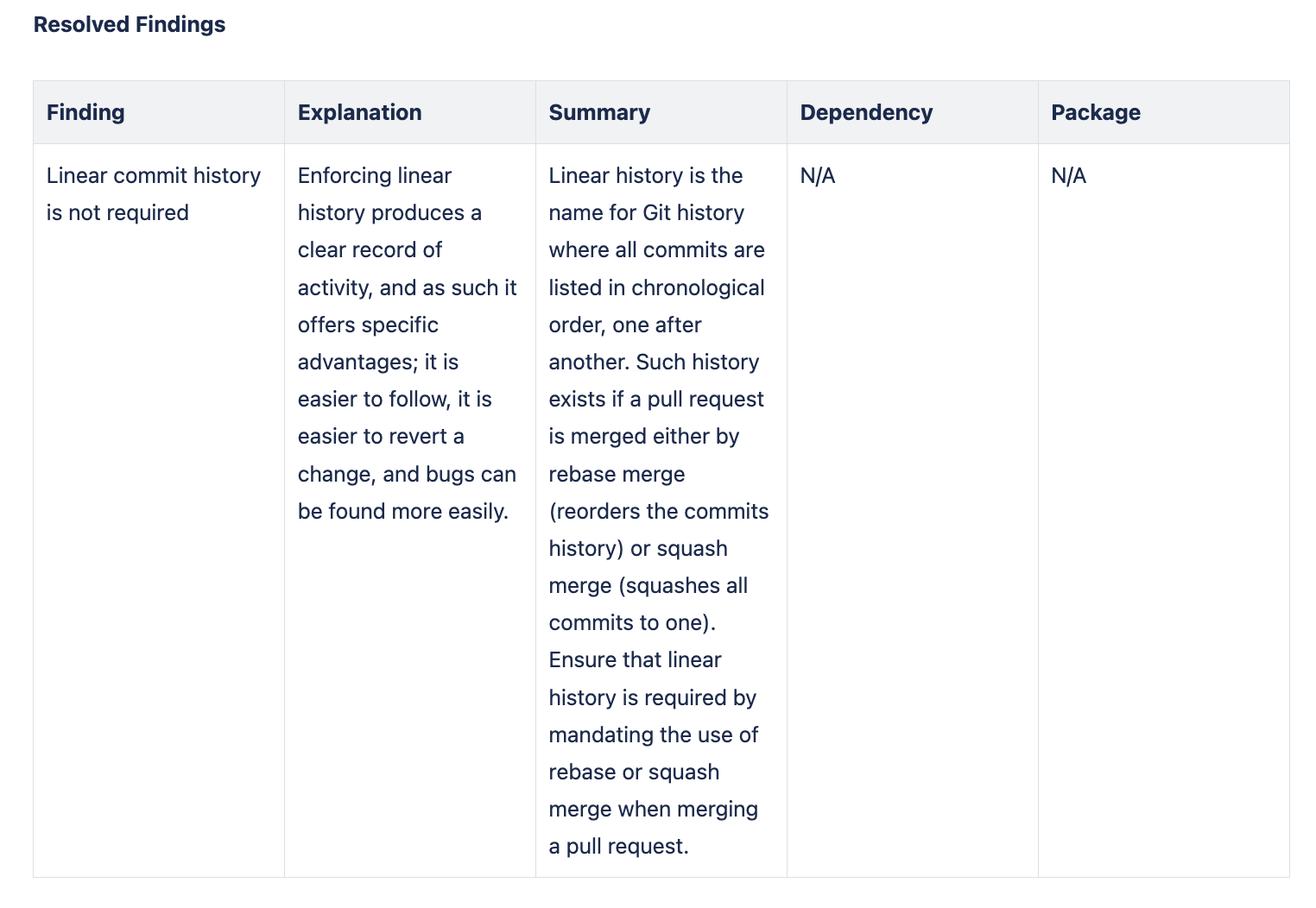
Why should you scan the baseline branches
Scan the baseline branches to:
-
Establish a security and quality baseline: Scanning the baseline branch helps establish a reference point for the security and quality standards of your code, allowing you to identify any deviations or new vulnerabilities in subsequent branches.
-
Detect inherited issues: By scanning the baseline branch, you can catch existing issues that might be inherited by other branches, ensuring that these problems are addressed before they proliferate throughout your development workflow. It will help you understand the current state of security.
-
Ensure consistency across development: Regularly scanning the baseline branch ensures that all branches derived from it start from a consistent and secure foundation, reducing the risk of introducing errors or vulnerabilities to your project.
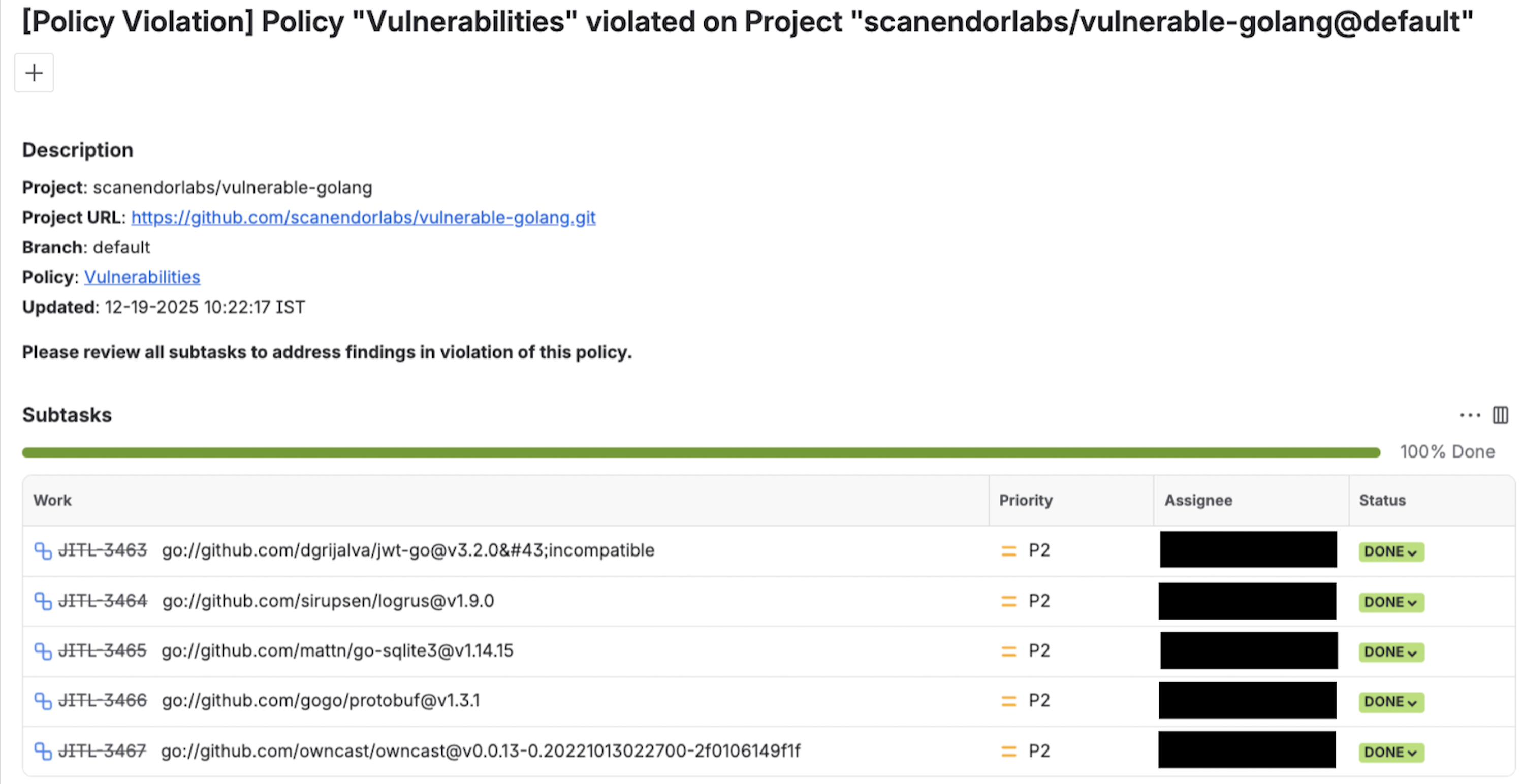
How to scan the baseline branch
Set up a trigger to initiate a scan whenever changes are merged into the baseline branch, or schedule daily scans to ensure continuous monitoring.
Perform a standard scan with additional configuration to enhance the process. By default, Endor Labs uses the first scanned branch as the default branch. You can override this behavior by using the --as-default-branch argument to designate one of your baseline branches as the default branch during your future scans, ensuring the correct context and parameters are applied for displaying statistics on the dashboards.
For more information, see the GitHub Actions templates you can use in your CI pipelines. The repository also includes examples of other CI tools.
Feature or hotfix branch
A feature or hotfix branch is a specialized branch in a version control system used to develop and integrate new features and bug fixes into the existing codebase. Changes are typically introduced into the code through pull requests.
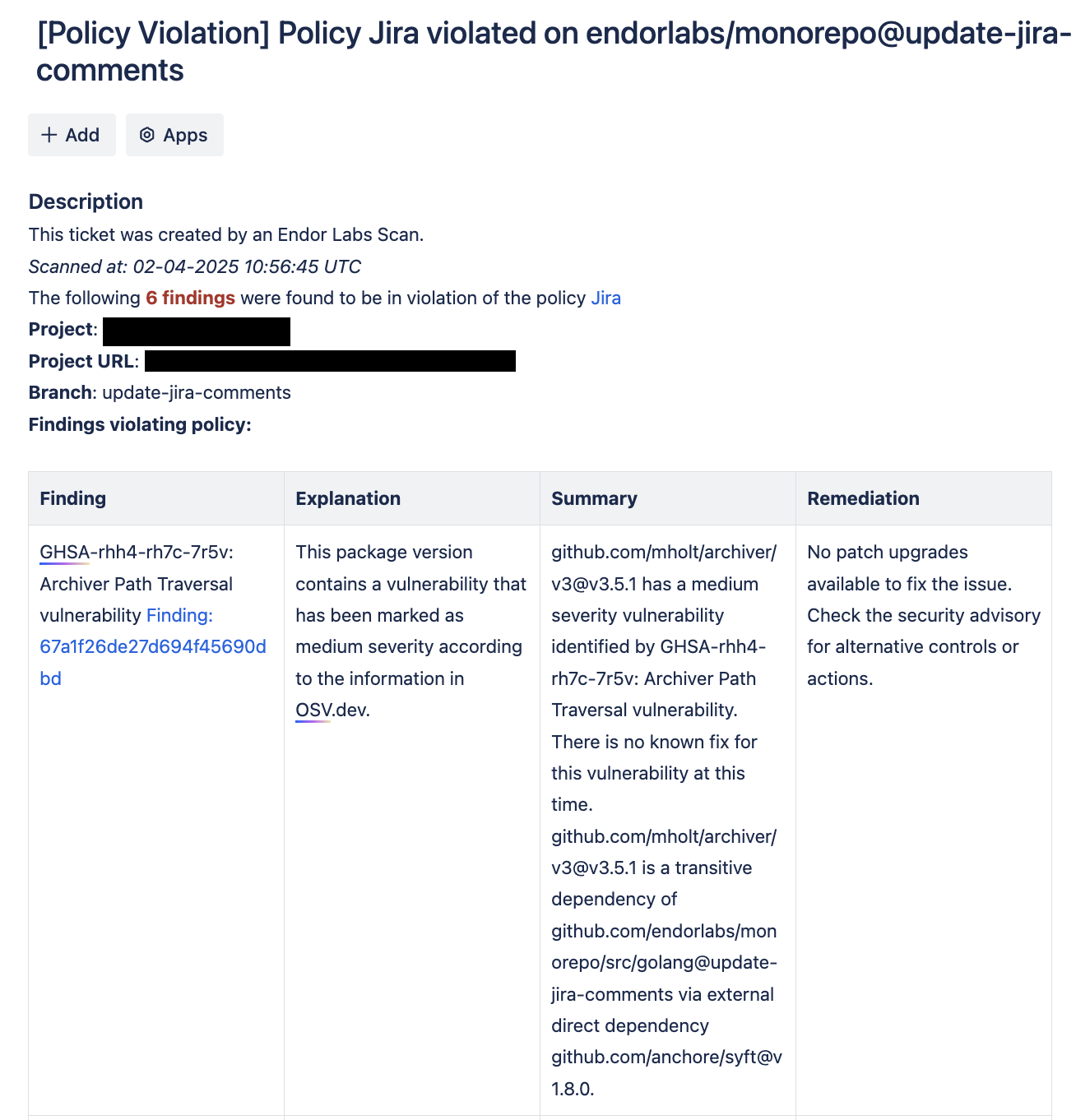
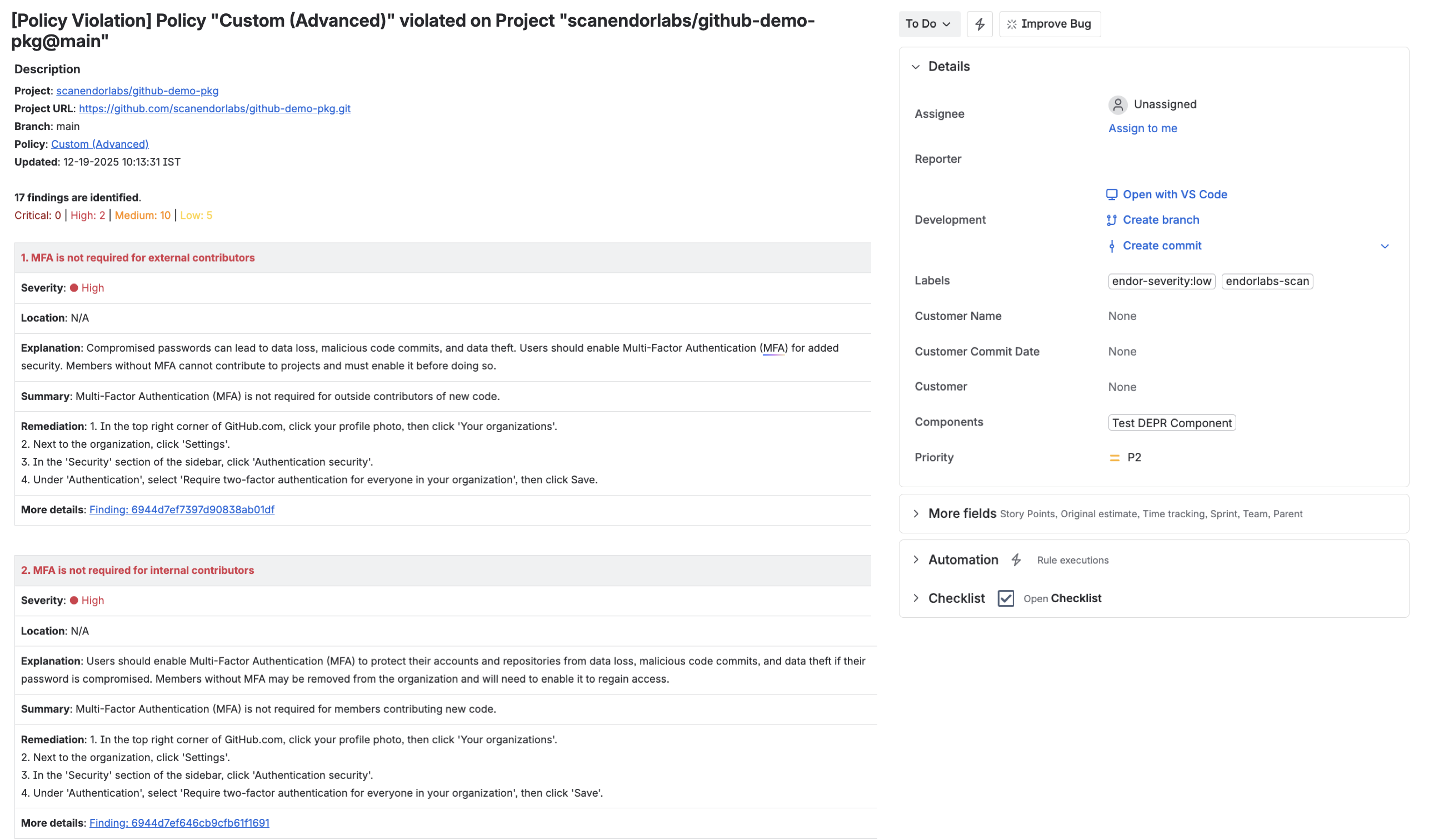
Why should you scan the feature branches through your pull requests
-
Prevent security vulnerabilities: Monitor pull requests to prevent the introduction of new vulnerable dependencies with known vulnerabilities, helping to maintain a secure codebase.
-
Enforce security policies: You can begin enforcing security policies to safeguard your codebase and ensure compliance with established best practices.
-
Perform incremental scans: Once you assess existing vulnerabilities in your baseline branch, you can perform incremental scans to optimize efficiency on your pull requests. Focus on these incremental scans to identify new vulnerabilities, and skip scanning pull requests if a package and its dependencies remain unchanged.
How to scan the feature branches through your pull requests
Set up PR scans to be triggered on pull requests to the baseline branch and specify the following arguments:
--pr(For GitHub Actions usepr: true)--pr-baseline: {baseline_branch}(For GitHub Actions usepr_baseline: true)--pr-incremental(For GitHub Actions useadditional_args: --pr-incremental)
For more information, see the templates that you can use in your CI pipelines.
For more details on how to perform endorctl scans and scan parameters, see Scan with Endor Labs and endorctl CLI.