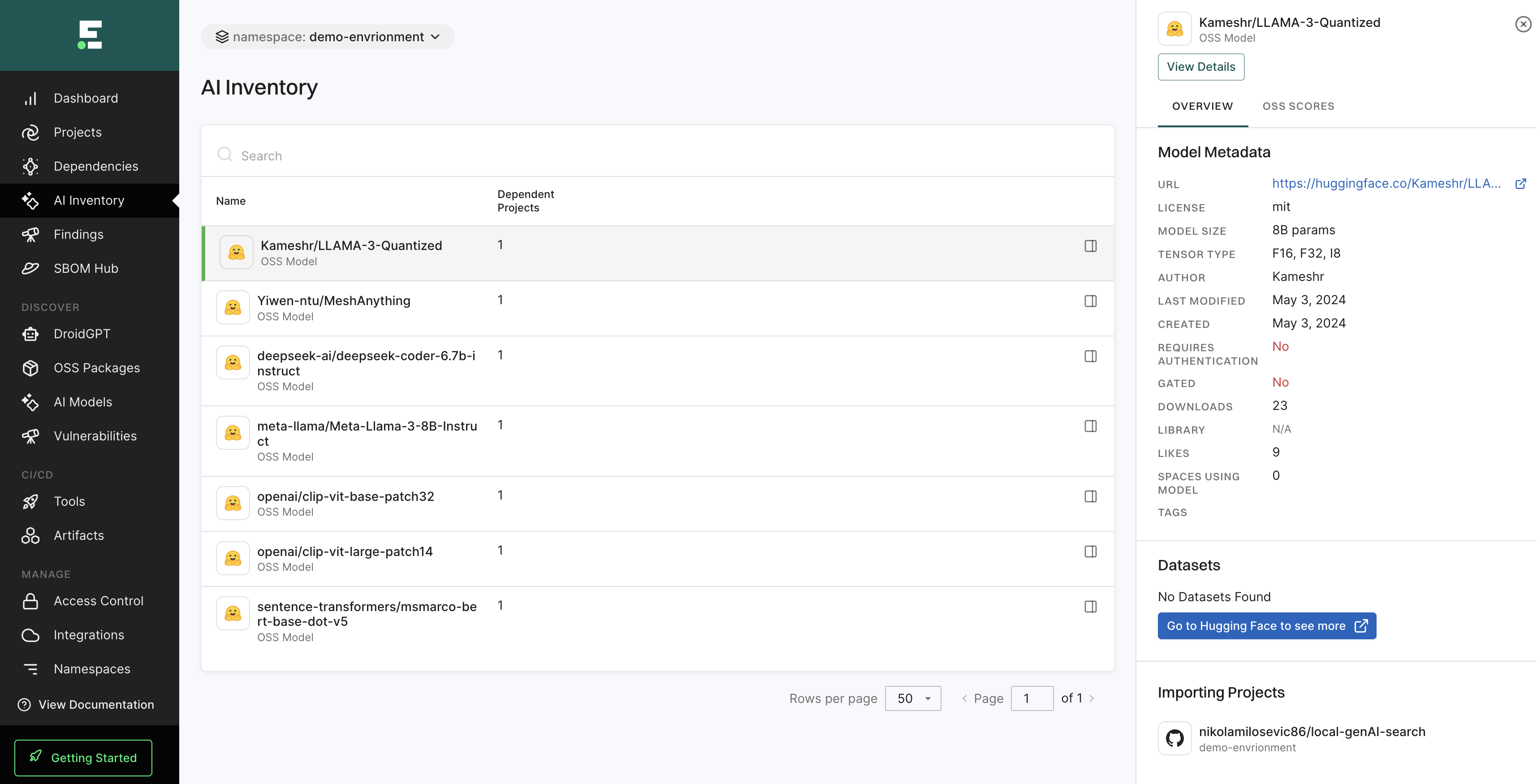
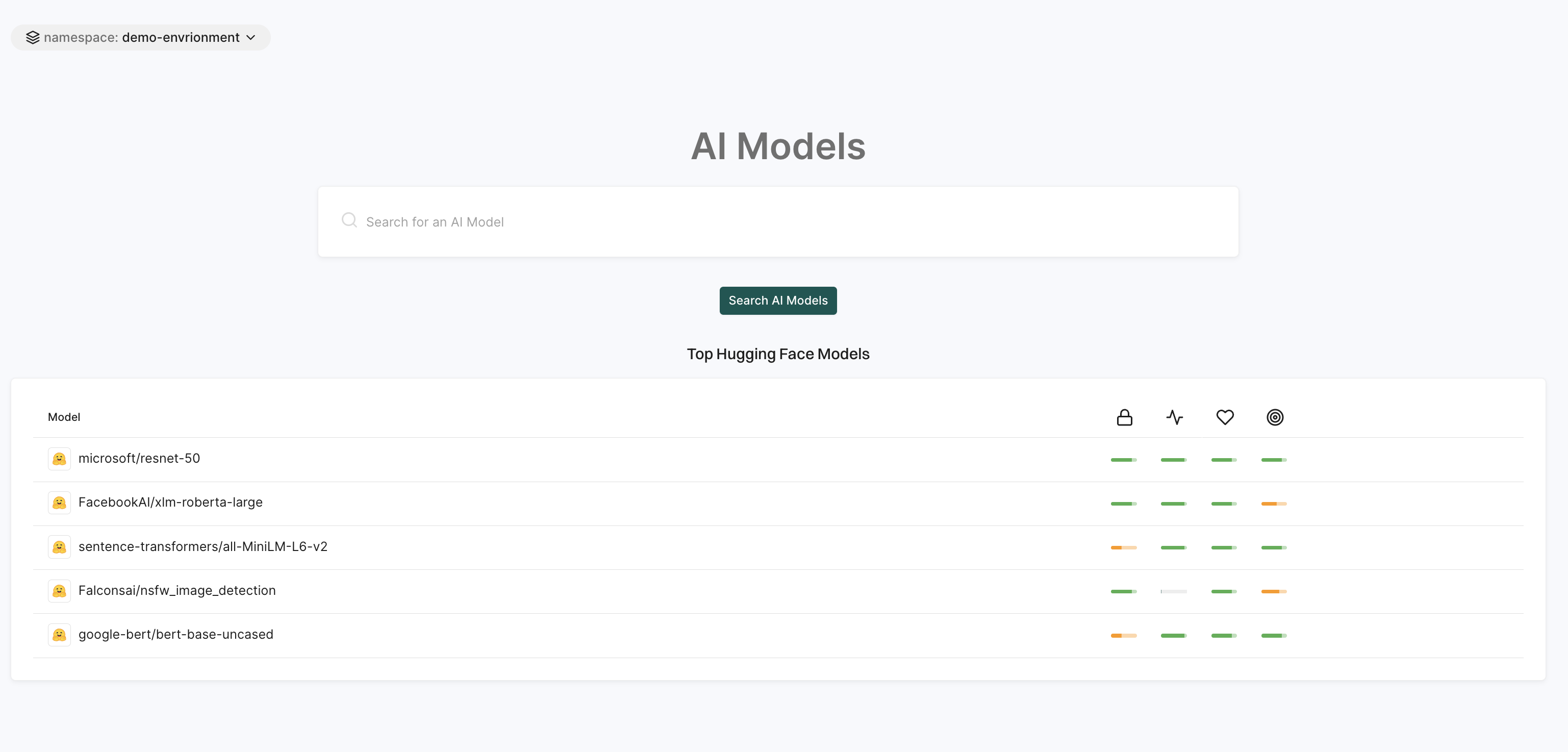
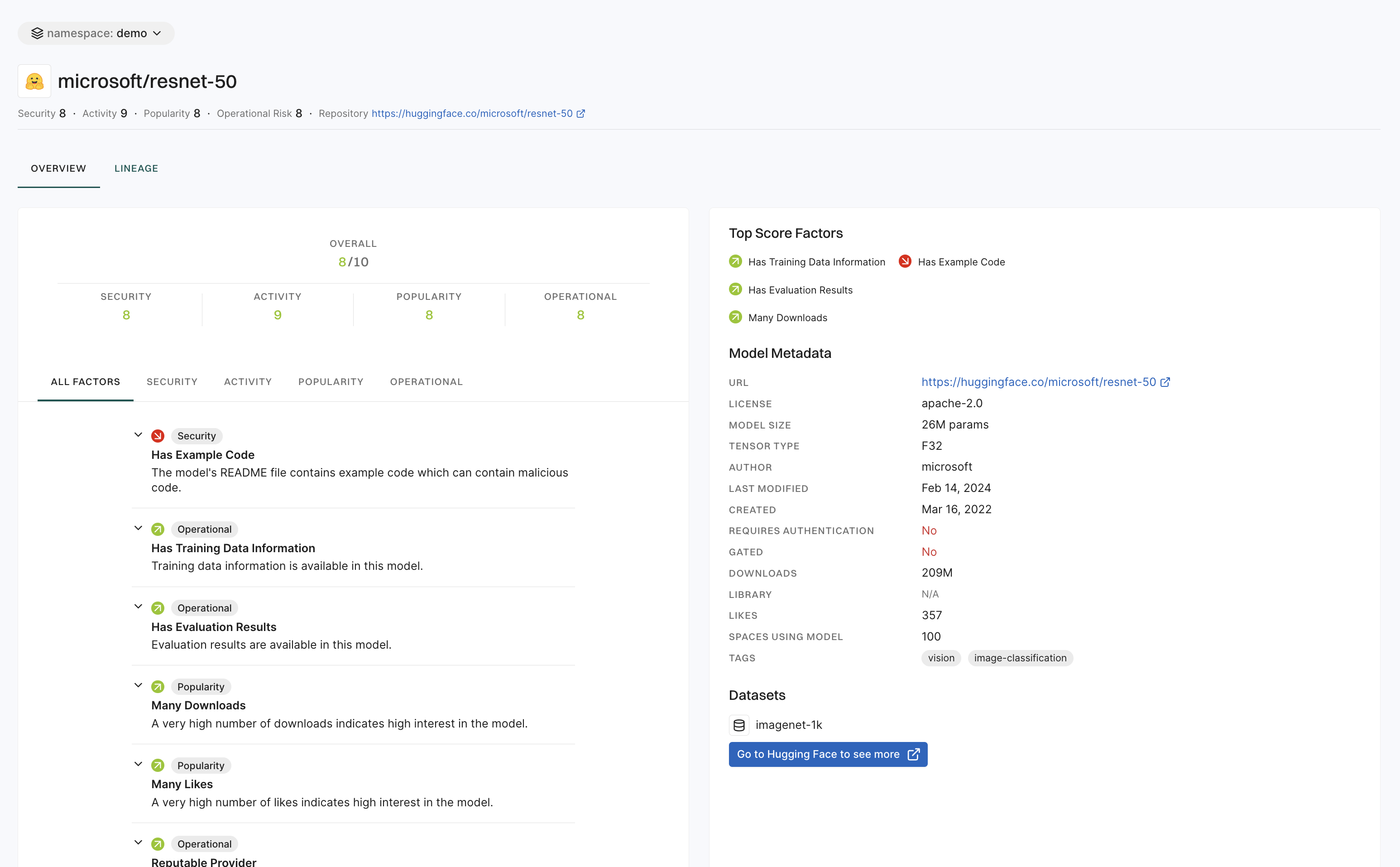
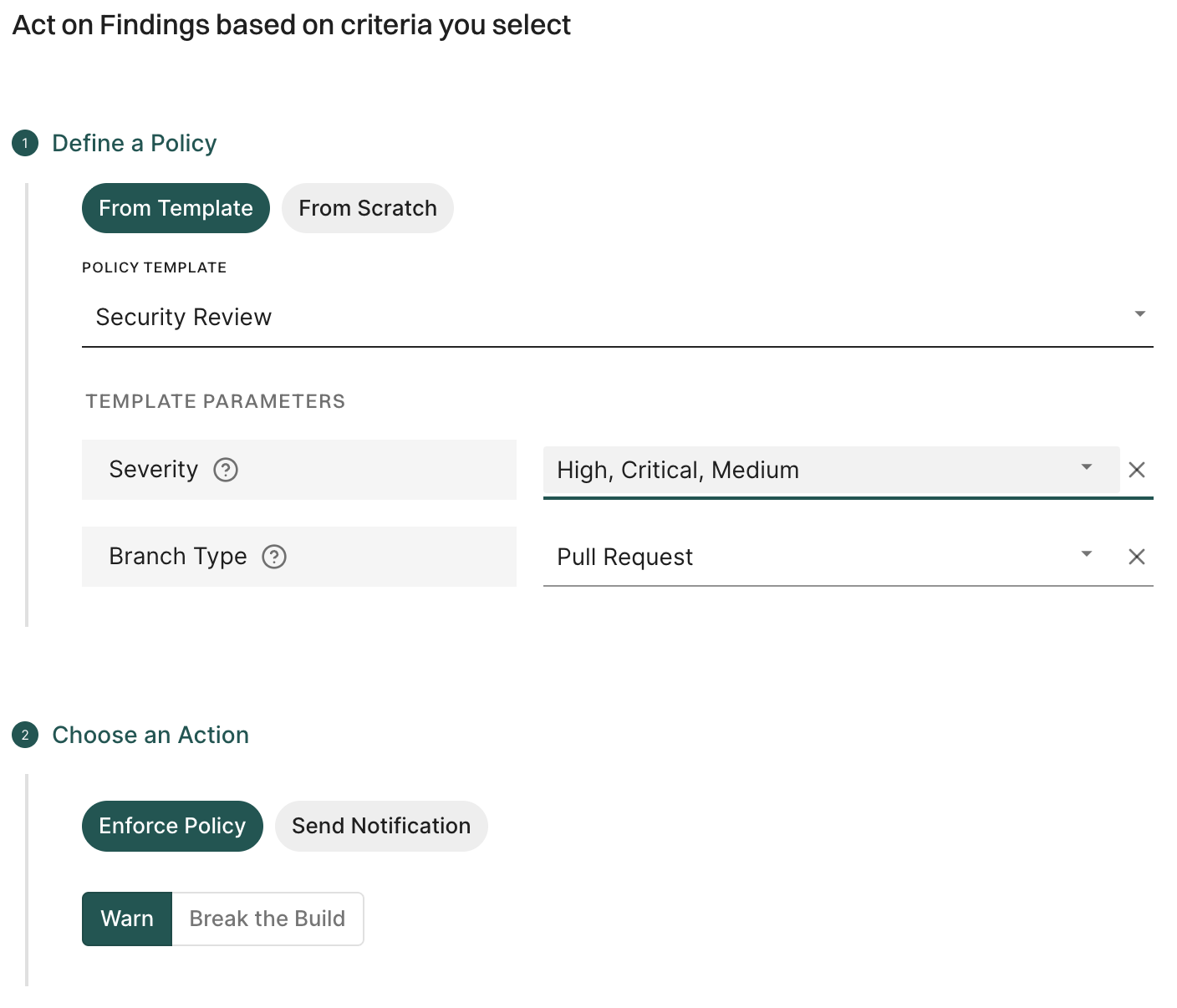
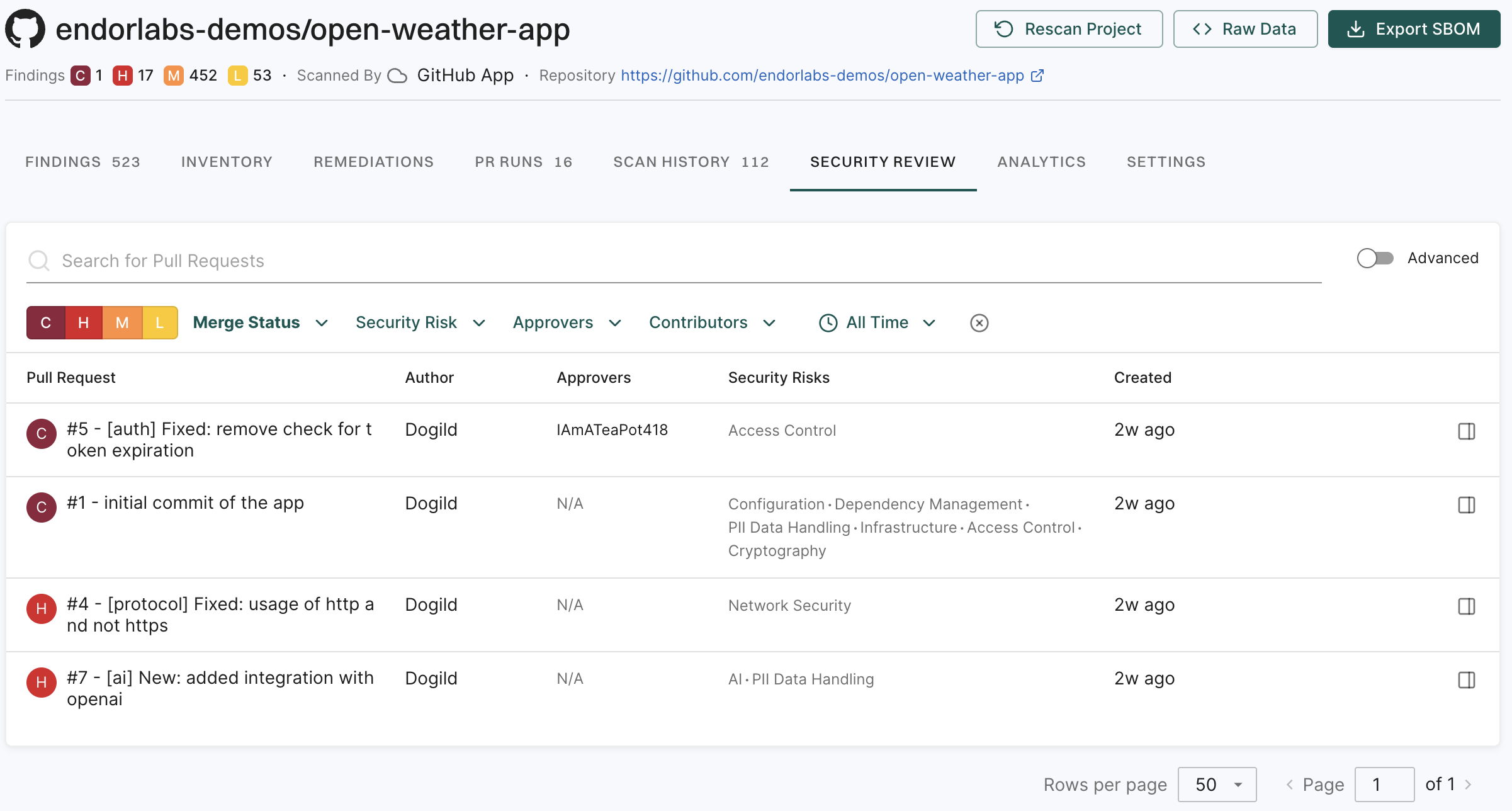
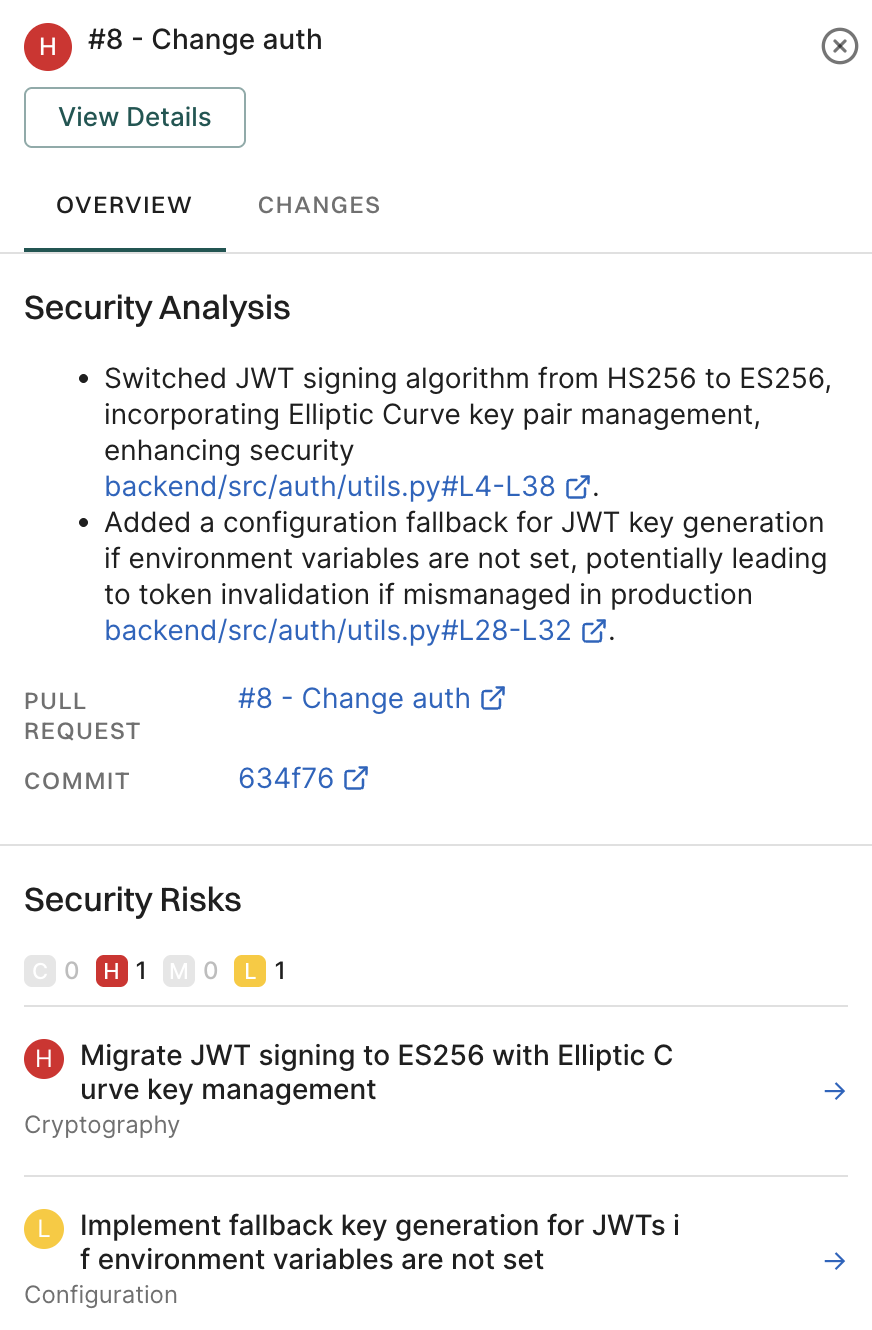
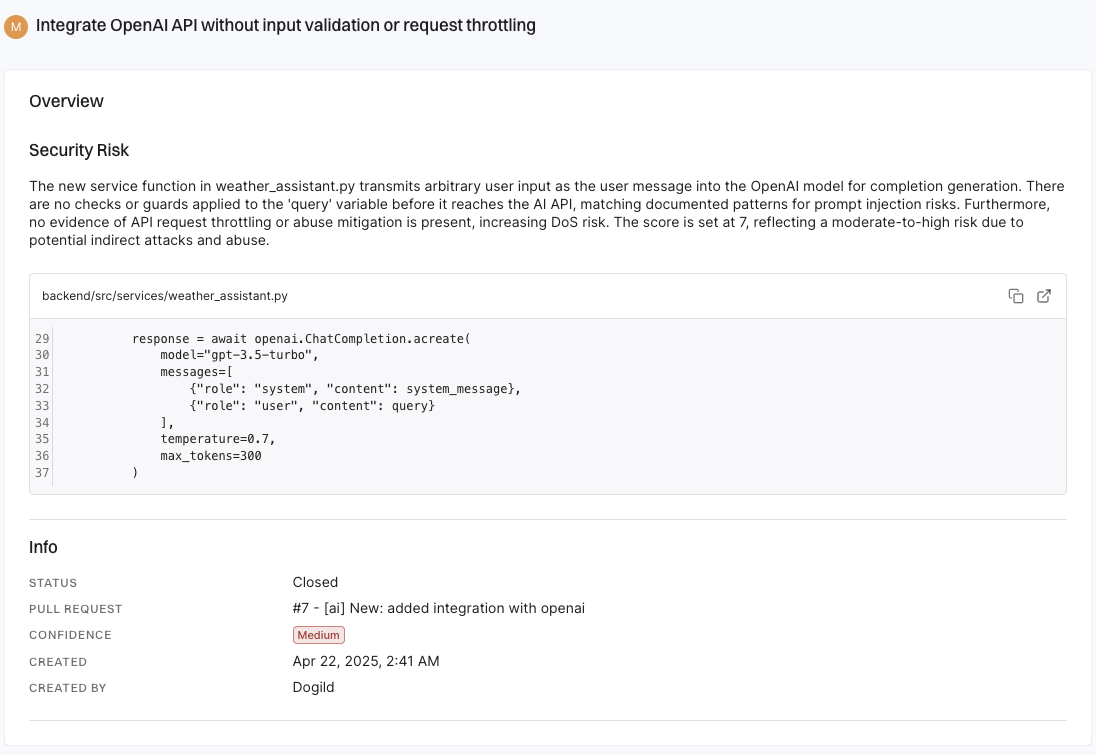
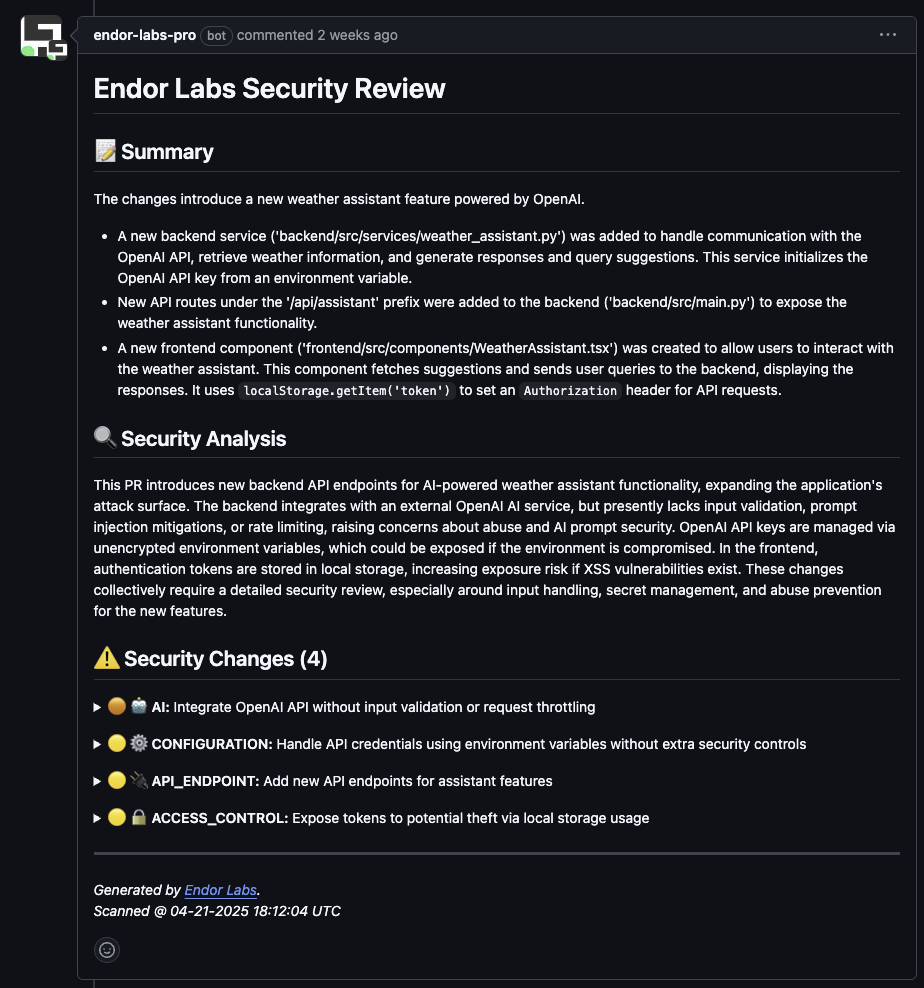
To evaluate AI models effectively, we use a multifactor scoring system that assesses popularity, activity, operational integrity, and security.
Each model is assigned a composite score based on the following criteria:
Popularity score factors
The popularity score reflects the model’s adoption and recognition within the AI community. Higher scores indicate greater usage and community engagement.
-
Number of downloads: More downloads indicate widespread adoption.
-
Number of likes: More likes suggest a positive reception from users.
-
Published papers: Models with linked academic papers receive higher credibility.
-
GitHub repository: Models with an associated GitHub repository score higher.
-
Number of spaces using the model: More integrations suggest broader utility.
Scoring approach for popularity score factors
-
Models with many downloads, likes, citations, and integrations score higher.
-
Models with fewer engagements score lower.
Activity score factors
The activity score measures how actively a model is discussed and maintained.
Scoring approach for activity score factors
Operational score factors
The operational score assesses the model’s reliability, transparency, and usability.
-
Reputable provider: Models from well-known sources score higher.
-
Model age: Older, well-maintained models may score higher, but outdated models may receive penalties.
-
Authorization requirements: Restricted-access models score lower for accessibility but may gain points for security.
-
Gated models: If a model requires special access, it may impact usability.
-
License information: Models with clear licensing receive higher scores.
-
License type: Open licenses (permissive, unencumbered) generally score higher than restrictive ones.
The following factors related to the availability of model metadata are also considered.
-
Metric information: Essential for model evaluation.
-
Dataset information: Transparency about training data boosts score.
-
Base model information: Important for derivative works.
-
Training data, fine-tuning, and alignment training information: Increases credibility.
-
Evaluation results: Demonstrates model performance.
Scoring approach for operational score factors
Models with comprehensive metadata, reputable providers, and clear licensing score higher.
Models with unclear ownership, restrictive access, or missing details score lower.
Security score factors
The security score evaluates potential risks associated with a model’s implementation and distribution.
-
Use of safe tensors: Secure tensor formats boost safety score.
-
Use of potentially unsafe files: Formats such as pickle, PyTorch, and Python code files pose security risks.
-
Typosquatting risks: Models that could be impersonating popular models receive lower scores.
-
Example code availability: Models that contain example code or code snippets can introduce potential issues and hence receive lower scores.
Scoring approach for security score factors
Models that follow best security practices such as safe tensors, clear documentation, or vetted repositories score higher.
Models receive lower scores if they use potentially unsafe formats such as pickle (.pkl) and unverified PyTorch (.pth) or show signs of typosquatting.
Final score calculation
Each category contributes to the overall model score. The final score is a weighted sum of these factors, with weights adjusted based on real-world relevance and risk impact.
Higher scores indicate well-documented, popular, actively maintained, and secure models, while lower scores highlight potential risks or lack of transparency.
This scoring system enables users to make informed decisions when selecting AI models for their projects.
Endor Labs continuously refines and expands its evaluation criteria; this document represents the current methodology snapshot.